











Konkurrenzprobleme gehören zu den schwierigsten Herausforderungen bei der Softwareentwicklung. Wenn mehrere Threads oder Prozesse mit gemeinsam genutzten Ressourcen interagieren, kann das resultierende Verhalten unvorhersehbar sein. Race Conditions treten auf, wenn das Ergebnis eines Systems von der relativen Zeitreihenfolge von Ereignissen abhängt, beispielsweise der Reihenfolge, in der Nachrichten verarbeitet werden, oder der Art und Weise, wie Daten zugegriffen werden. Diese logischen Fehler zeigen sich oft nicht bei der normalen Testphase, sondern erst unter bestimmten Last- oder Zeitbedingungen. Um dies zu bewältigen, benötigen Ingenieure Werkzeuge, die Interaktionen über die Zeit und Zustandsänderungen visualisieren. Kommunikationsdiagramme bieten einen strukturierten Ansatz zur Abbildung dieser Interaktionen.
Das Debuggen der Logik ohne visuelle Hilfsmittel ist wie die Orientierung in einer komplexen Stadt ohne Karte. Man weiß, wohin man möchte, aber der Weg ist durch Kreuzungen und Verkehrsströme verdeckt. Im Kontext der Systemgestaltung besteht der „Verkehr“ aus asynchronen Nachrichten und Zustandsübergängen. Durch die Verwendung von Kommunikationsdiagrammen können Entwickler den Steuerungs- und Datenfluss explizit nachverfolgen. Dieser Leitfaden untersucht, wie man diese Diagramme nutzt, um Race Conditions zu erkennen, bevor sie Produktionsumgebungen beeinträchtigen.
Verständnis von Race Conditions in der Systemlogik 🧠
Eine Race Condition besteht dann, wenn zwei oder mehr Operationen um dieselbe Ressource konkurrieren und der Endzustand von der Reihenfolge oder dem Zeitpunkt ihrer Ausführung abhängt. Dies ist nicht einfach ein Programmierfehler, sondern ein logischer Fehler in der Gestaltung der Interaktion zwischen Komponenten. Betrachten Sie eine Situation, in der zwei Prozesse gleichzeitig versuchen, einen gemeinsam genutzten Zähler zu aktualisieren. Wenn der Lese-Ändere-Schreib-Vorgang nicht atomar ist, kann eine Aktualisierung verloren gehen.
- Time-of-check to Time-of-use (TOCTOU): Eine klassische Sicherheitslücke, bei der der Zustand einer Ressource zu einem Zeitpunkt überprüft wird, aber die Ressource zu einem späteren Zeitpunkt genutzt wird, wobei sie dazwischen möglicherweise verändert wurde.
- Verzahnte Ausführung: Threads führen Anweisungen in einer unvorhersehbaren Reihenfolge aus, was zu inkonsistenten Datenzuständen führt.
- Nachrichtenreihenfolge: In verteilten Systemen können Nachrichten in falscher Reihenfolge eintreffen, was dazu führt, dass Logikzweige auf veralteten Informationen basieren.
Traditionelle Debugging-Tools konzentrieren sich oft auf Stack-Trace oder Speicherabbilder. Obwohl sie nützlich sind, zeigen sie nicht von Natur aus die kausalen Beziehungen zwischen verschiedenen Systemkomponenten. Eine Race Condition ist oft ein Beziehungsproblem, kein reines Variablenproblem. Daher ist ein Diagramm, das die Beziehungen und den Nachrichtenfluss betont, effektiver für die Diagnose.
Die Kraft von Kommunikationsdiagrammen 📊
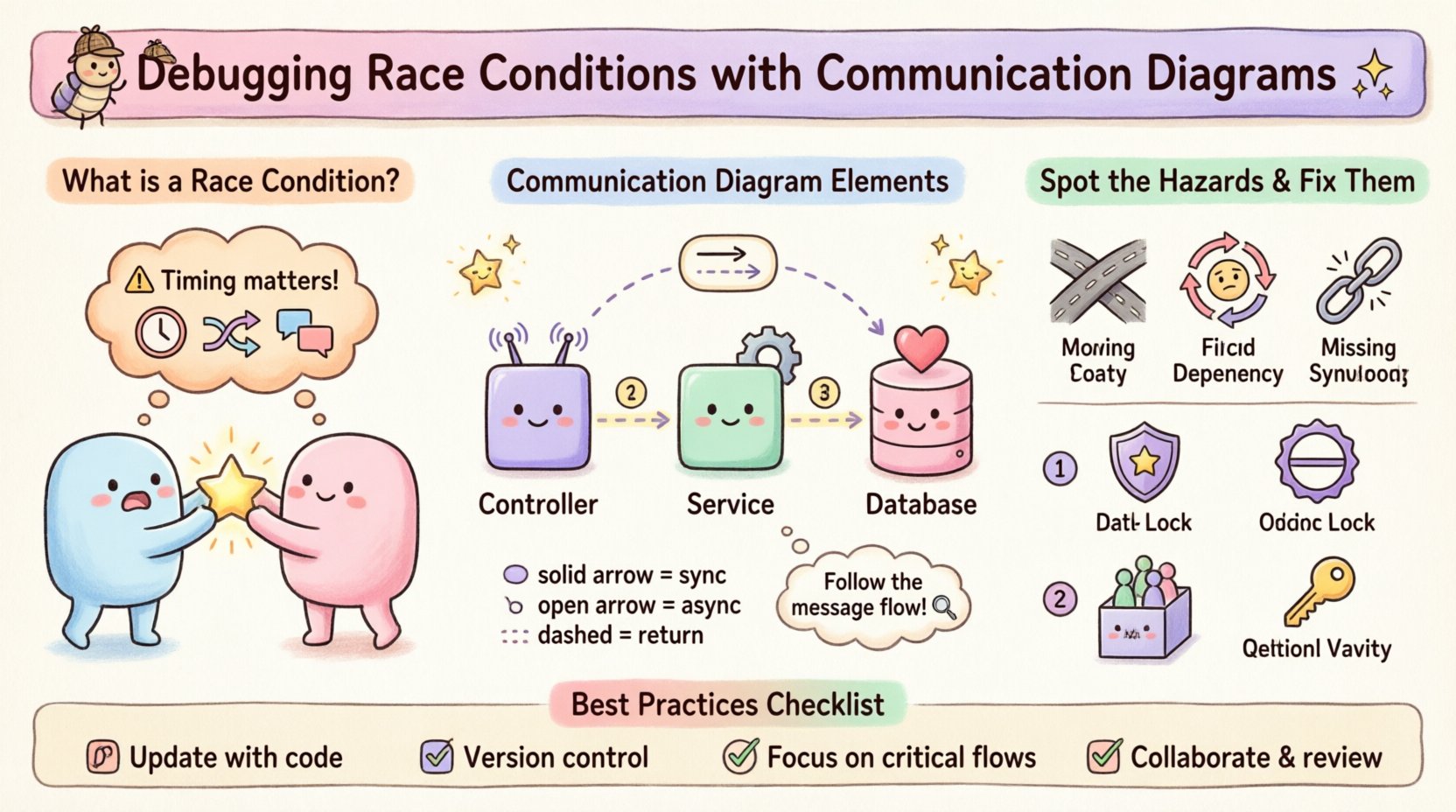
Kommunikationsdiagramme, früher als Zusammenarbeitsdiagramme in UML 1.x bekannt, konzentrieren sich auf die strukturelle Organisation von Objekten und die Nachrichten, die sie untereinander senden. Im Gegensatz zu Sequenzdiagrammen, die die Zeit vertikal priorisieren, legen Kommunikationsdiagramme den Fokus auf die strukturellen Verbindungen zwischen Objekten. Diese Perspektive ist entscheidend für die Erkennung von Race Conditions, da sie gemeinsame Verbindungen hervorhebt.
Beim Debuggen suchen Sie nach Punkten, an denen mehrere Pfade zusammenlaufen. In einem Kommunikationsdiagramm sind diese Konvergenzpunkte oft die Ursachen für Konflikte. Das Diagramm besteht aus Objekten, Verbindungen und Nachrichten. Jede Nachricht stellt einen Aufruf oder ein Signal dar. Durch die Annotation dieser Nachrichten mit Zeitbeschränkungen oder Prioritätsstufen können Sie die Ausführungsumgebung simulieren.
- Objekte: Stellen die aktiven Entitäten im System dar, beispielsweise einen Controller, einen Service oder eine Datenbank.
- Verbindungen: Definieren die strukturellen Pfade, über die Nachrichten zwischen Objekten fließen.
- Nachrichten: Stellen den Logikfluss dar. Sie können synchron (blockierend) oder asynchron (Feuern-und-Vergessen) sein.
Die visuelle Anordnung ermöglicht es Ihnen, die „Hub“-Objekte zu erkennen. Das sind die Objekte, die mit den meisten anderen Entitäten interagieren. Eine hohe Verbindungsdichte korreliert oft mit einem höheren Risiko für Konkurrenzprobleme. Indem Sie diese Hub-Objekte isolieren, können Sie Ihre Debugging-Bemühungen dort konzentrieren, wo sie am wichtigsten sind.
Die Bühne für das Debuggen vorbereiten 🛠️
Bevor Sie das Diagramm zeichnen, müssen Sie den Umfang des Problems verstehen. Race Conditions stammen oft aus spezifischen Workflows. Identifizieren Sie den kritischen Pfad, an dem die Dateninkonsistenz auftritt. Zum Beispiel, wenn ein Benutzerprofil-Update intermittierend fehlschlägt, verfolgen Sie den Fluss vom API-Endpunkt bis zur Datenbank.
Hier ist eine Checkliste, um Ihre Umgebung für die diagrammatische Analyse vorzubereiten:
- Definieren Sie die Akteure: Listen Sie alle externen Systeme oder Benutzer auf, die Anfragen initiieren.
- Identifizieren Sie interne Objekte: Zerlegen Sie die interne Architektur in logische Komponenten (z. B. Cache, API, Worker).
- Listen Sie die Nachrichten auf: Nennen Sie die spezifischen Funktionsaufrufe oder Ereignisse, die während des Workflows auftreten.
- Markieren Sie gemeinsam genutzte Ressourcen: Heben Sie alle Datenbanktabellen, Speichervariablen oder Dateisperren hervor, die von mehreren Objekten zugegriffen werden.
Sobald der Umfang definiert ist, können Sie mit der Erstellung des Diagramms beginnen. Das Ziel ist nicht, ein perfektes architektonisches Modell zu erstellen, sondern ein Debugging-Element. Vereinfachen Sie, wenn nötig. Wenn ein Komponente nicht zur Race Condition beiträgt, lassen Sie sie weg. Klarheit ist in dieser Phase wichtiger als Vollständigkeit.
Schritt für Schritt: Abbildung des Ablaufs 🔍
Die Erstellung des Diagramms für das Debugging erfordert eine spezifische Methodik. Sie kartieren Logik, nicht nur Struktur. Folgen Sie diesen Schritten, um ein wirksames Debugging-Element zu erstellen.
1. Initiator und Ziel platzieren
Beginnen Sie damit, das Objekt, das die Anfrage initiiert, links oder oben zu platzieren. Platzieren Sie das primäre Objekt, das betroffen ist, rechts oder unten. Dadurch wird die Richtung des Flows festgelegt. Zum Beispiel, wenn ein UserService ruft eine Datenbank, das BenutzerObjekt sendet eine Nachricht an die Datenbank.
2. Zwischenobjekte hinzufügen
Zeichnen Sie alle Middleware- oder Caching-Ebenen auf. In einer Race-Condition-Situation ist eine Cach-Ebene ein häufiger Verdächtiger. Wenn der Cache vor der Datenbank aktualisiert wird, kann ein veraltetes Lesen auftreten. Wenn die Datenbank vor dem Cache aktualisiert wird, kann der Cache alte Daten anzeigen. Zeichnen Sie eine Verbindung für jeden Zwischenschritt.
3. Nachrichtentypen kennzeichnen
Unterscheiden Sie zwischen synchronen und asynchronen Nachrichten. Synchronen Nachrichten liegt ein Wartezustand zugrunde. Asynchrone Nachrichten implizieren ein „senden und vergessen“-Verhalten. Race Conditions entstehen oft aus asynchronen Aufrufen, bei denen die Antwort erwartet wird, aber nicht garantiert ist, dass sie in der richtigen Reihenfolge eintreffen.
- Synchron: Verwenden Sie eine durchgezogene Linie mit einer durchgezogenen Pfeilspitze.
- Asynchron: Verwenden Sie eine durchgezogene Linie mit einer offenen Pfeilspitze.
- Rückmeldungen: Verwenden Sie eine gestrichelte Linie mit einer offenen Pfeilspitze.
4. Verbindungen beschriften
Weisen Sie jeder Nachricht eine Nummer zu, um die Reihenfolge anzugeben. Dies ist für das Debugging entscheidend. In einem Kommunikationsdiagramm wird die Reihenfolge durch die Nummern impliziert, nicht nur durch die vertikale Position. Stellen Sie sicher, dass die Nummern die logische Ausführungsreihenfolge so genau wie möglich widerspiegeln.
Identifizieren von Konkurrenzgefahren im Diagramm ⚠️
Sobald das Diagramm gezeichnet ist, müssen Sie es auf spezifische Muster analysieren, die Instabilität anzeigen. Achten Sie auf diese strukturellen Warnzeichen.
- Zusammenführende Pfade: Wenn zwei verschiedene Nachrichtenflüsse zu demselben Objekt führen, um dieselben Daten zu ändern, ist eine Rennbedingung möglich. Dies deutet auf mehrere Einstiegspunkte in einen kritischen Abschnitt hin.
- Zirkuläre Abhängigkeiten: Wenn Objekt A Objekt B aufruft und Objekt B innerhalb derselben logischen Transaktion Objekt A aufruft, kann das System sich verhängen oder unvorhersehbar verhalten.
- Fehlende Synchronisation: Wenn ein kritischer Update asynchron gesendet wird, ohne vor dem nächsten Schritt eine Bestätigungsnachricht zu erhalten, könnte die nachfolgende Logik mit veralteten Daten fortfahren.
Berücksichtigen Sie das „Double-Check Locking“-Muster. Es ist eine häufige Optimierung, die ohne geeignete Speicherbarrieren fehlschlägt. In einer Darstellung sieht dies aus wie eine Prüfnachricht, gefolgt von einer Aktualisierungsnachricht. Wenn ein anderer Thread die Prüfung zwischen den beiden Schritten durchführt, erfolgt die Aktualisierung unnötigerweise.
Analyse der Nachrichtenreihenfolge und der Zeitpunkte ⏱️
Die Zeit ist die unsichtbare Variable bei Rennbedingungen. Kommunikationsdiagramme können Zeitbeschränkungen mithilfe von Notizen oder spezifischen Anmerkungen darstellen. Obwohl sie keine genauen Millisekunden anzeigen, zeigen sie logische Reihenfolge an.
Verwenden Sie die folgenden Strategien zur Analyse der Zeitpunkte:
- Parallelität:Zeichnen Sie parallele Zweige, um gleichzeitige Ausführung darzustellen. Wenn zwei Zweige auf eine gemeinsame Ressource zusteuern, bestimmt die Reihenfolge des Eintreffens das Ergebnis.
- Zeitüberschreitungen:Fügen Sie Anmerkungen hinzu, die erwartete Zeitüberschreitungen anzeigen. Wenn eine Nachricht innerhalb eines bestimmten Zeitraums nicht zurückkehrt, versucht das System erneut? Wiederholungen können doppelte Aktualisierungen verursachen.
- Eventuelle Konsistenz: Wenn das System auf eventuelle Konsistenz angewiesen ist, muss das Diagramm die Verzögerung zwischen der Schreiboperation und der Lesbarkeit anzeigen. In dieser Verzögerung verbergen sich Rennbedingungen.
Zum Beispiel könnte ein Benachrichtigungsdienst eine E-Mail senden, nachdem eine Zahlung bestätigt wurde, aber wenn die Zahlungsbestätigung asynchron erfolgt, könnte die E-Mail gesendet werden, bevor das Geld tatsächlich gesichert ist. Das Diagramm sollte die Lücke zwischen dem Ereignis der Zahlungsbestätigung und dem E-Mail-Auslöser explizit anzeigen.
Häufige Muster, die zu Instabilität führen 🔄
Bestimmte architektonische Muster sind anfällig für Rennbedingungen. Ihre Erkennung in Ihrem Diagramm kann den Debugging-Prozess beschleunigen.
| Muster | Risikobeschreibung | Diagramm-Indikator |
|---|---|---|
| Lesen-Ändern-Schreiben | Zwei Prozesse lesen denselben Wert, ändern ihn und schreiben ihn zurück. Der zweite Schreibvorgang überschreibt den ersten. | Mehrere Nachrichten, die auf denselben Datenbestand zielen, ohne dass ein Sperrmechanismus dargestellt ist. |
| Feuern-und-Verlassen | Ein Ereignis wird ausgelöst, ohne auf eine Bestätigung zu warten. Die nachfolgende Logik geht von einem Erfolg aus. | Asynchrone Nachrichtenpfeil ohne Rückweg oder Bestätigungsnachricht. |
| Cache-Invalidierung | Daten werden in der Datenbank aktualisiert, aber nicht im Cache, oder umgekehrt. | Parallele Pfade zu Datenbank und Cache ohne Synchronisationspunkt. |
| Idempotenz-Fehler | Eine Anfrage wird wiederholt, was duplizierter Aktionen zur Folge hat. | Schleifenpfeile, die Wiederholungen ohne Überprüfung einer eindeutigen Transaktions-ID anzeigen. |
Wenn Sie diese Muster in Ihrer Diagramm sehen, halten Sie an. Fragen Sie sich: „Was passiert, wenn Nachricht B vor Nachricht A eintrifft?“ oder „Was passiert, wenn das System zwischen Schritt 3 und Schritt 4 abstürzt?“ Diese Fragen offenbaren oft logische Lücken.
Minderungsstrategien nach Identifizierung 🛡️
Sobald die Rennbedingung visualisiert und verstanden ist, können Sie strukturelle Änderungen vornehmen. Das Diagramm hilft Ihnen, festzulegen, welche architektonische Änderung angemessen ist.
- Sperrmechanismen: Wenn das Diagramm gleichzeitigen Zugriff auf eine Ressource zeigt, führen Sie ein Sperr-Objekt ein. Im Diagramm erscheint dies als Nachricht an einen Sperr-Manager, bevor auf die Daten zugegriffen wird.
- Optimistische Sperrung: Statt zu blockieren, verwenden Sie Versionsnummern. Das Diagramm sollte eine Überprüfung der Versionsnummer vor der Schreiboperation zeigen.
- Warteschlangen: Wenn das Problem durch zu viele parallele Anfragen verursacht wird, führen Sie eine Nachrichtenwarteschlange ein. Das Diagramm ändert sich von direkten Aufrufen zu einem Warteschlangen-Objekt, das die Nachrichten seriellisiert.
- Idempotenz-Schlüssel: Stellen Sie sicher, dass jede Anfrage einen eindeutigen Bezeichner hat. Das Diagramm sollte zeigen, dass diese ID übergeben und gegen bestehende Aufzeichnungen überprüft wird.
Die Aktualisierung des Diagramms nach der Anwendung dieser Korrekturen ist entscheidend. Es dient als Dokumentation für zukünftige Entwickler. Es beweist, dass das Design überprüft wurde und das Risiko gemindert wurde.
Best Practices zur Diagramm-Wartung 📝
Diagramme sind lebende Dokumente. Wenn sie veraltet sind, verlieren sie ihren Wert als Debugging-Tools. Halten Sie sie relevant, indem Sie diese Praktiken befolgen.
- Aktualisierung bei Code-Änderungen: Wenn sich der Logikfluss ändert, muss auch das Diagramm geändert werden. Lassen Sie das Diagramm nicht von der Realität abweichen.
- Versionskontrolle: Speichern Sie Diagramme zusammen mit dem Code-Repository. Dadurch ist der Debugging-Kontext verfügbar, wenn neue Entwickler hinzukommen.
- Fokus auf Abläufe: Zeichnen Sie nicht jede Funktion auf. Konzentrieren Sie sich auf die kritischen Pfade, an denen Konkurrenz möglich ist.
- Kooperieren: Überprüfen Sie das Diagramm mit Kollegen. Ein frischer Blick könnte einen Pfad entdecken, den Sie übersehen haben, wie beispielsweise eine vergessene Hintergrundaufgabe.
Die Dokumentation sollte knapp sein. Verwenden Sie Standardnotationen, damit jeder im Team das Diagramm ohne Legende verstehen kann. Konsistenz in der Notation verringert die kognitive Belastung beim Debuggen.
Vergleich: Ablauf- vs. Kommunikationsdiagramme 📋
Während Ablaufdiagramme häufiger verwendet werden, bieten Kommunikationsdiagramme spezifische Vorteile für das Debuggen von Rennbedingungen. Beide verwenden ähnliche Notationen, betonen aber unterschiedliche Aspekte.
- Ablaufdiagramme: Betonen Sie die Zeit. Sie zeigen eine strenge vertikale Zeitachse. Sie eignen sich hervorragend, um die genaue Reihenfolge von Ereignissen zu verstehen, können sich aber bei komplexen Objektbeziehungen verwirrend gestalten.
- Kommunikationsdiagramme:Betonen Sie die Struktur. Sie zeigen, wie Objekte miteinander verbunden sind. Sie eignen sich besser, um das „Netzwerk“ der Interaktionen zu erkennen und gemeinsam genutzte Knotenpunkte zu identifizieren.
Bei Race-Conditions ist die strukturelle Sichtweise oft aufschlussreicher. Ein Sequenzdiagramm könnte zeigen, dass zwei Nachrichten zur gleichen Zeit erfolgten, aber ein Kommunikationsdiagramm zeigt, dass beide Nachrichten an dasselbe Objekt gingen. Diese strukturelle Erkenntnis weist direkt auf den Ressourcenkonflikt hin.
Verwenden Sie die folgenden Kriterien zur Auswahl:
- Wählen Sie Sequenzdiagramme: Wenn die genaue zeitliche Reihenfolge komplex und linear ist.
- Wählen Sie Kommunikationsdiagramme: Wenn die Beziehung zwischen Objekten komplex und nicht-linear ist.
Abschließende Gedanken zur Logik-Debugging 🎯
Das Debugging von Logik erfordert mehr als nur das Nachverfolgen von Code. Es erfordert das Verständnis der Interaktionen zwischen Komponenten. Kommunikationsdiagramme bieten einen Überblick über diese Interaktionen. Durch die Visualisierung des Nachrichtenflusses und der Ressourcenfreigabe können Sie Race-Conditions erkennen, bevor sie zu Datenkorruption führen.
Der Prozess ist iterativ. Zeichnen Sie das Diagramm, analysieren Sie die Pfade, identifizieren Sie die Gefahren und verfeinern Sie anschließend die Logik. Dieser Zyklus stellt sicher, dass das System auch unter gleichzeitiger Belastung robust bleibt. Vermeiden Sie die Versuchung, sich ausschließlich auf automatisierte Tests zu verlassen, da diese häufig zeitabhängige Randfälle übersehen. Die Visualisierung der Logik zwingt Sie, sich direkt mit dem Konkurrenzmodell auseinanderzusetzen.
Die Einführung dieses Ansatzes fördert ein tieferes Verständnis Ihres Systems. Er verlagert den Fokus von der Behebung von Symptomen hin zur Behebung des zugrundeliegenden Designs. Mit zunehmender Erfahrung mit diesen Diagrammen werden Sie feststellen, dass Sie potenzielle Konkurrenzprobleme bereits vor dem Schreiben einer einzigen Codezeile vorhersagen können. Diese proaktive Haltung ist das Kennzeichen einer reifen Ingenieurpraxis.
Denken Sie daran, das Ziel ist Klarheit. Wenn das Diagramm verwirrend ist, ist die Logik wahrscheinlich fehlerhaft. Vereinfachen Sie das Modell, bis der Datenpfad eindeutig ist. Mit klaren Diagrammen werden Race-Conditions zu sichtbaren Problemen, die mit Vertrauen gelöst werden können.