











実務経験のあるソフトウェアアーキテクトによる | 2026年4月
はじめに:現代のソフトウェア設計におけるテキスト解析の重要性
ビジネス要件と技術的実装の間を10年以上かけてつなげてきた者として、私はソフトウェア開発で最も難しいのはコードを書くことではなく、理解することだと常に信じています。何を構築すべきかということです。多くの場合、要件は自然言語で書かれた濃密な段落として到着し、開発者は明確な手法なしに意図を読み解き、エンティティを特定し、関係性をモデル化する必要があります。
そのため、Visual Paradigmのテキスト解析を用いた問題記述からUMLモデルへの変換チュートリアルを実際に試してみることに、本気でワクワクしました。このガイドは、サトゥルン・インターナショナルの駐車場セキュリティシステムという現実的なシナリオを扱い、平易な英語からクラス、関係性、相互作用を抽出する構造化されたアプローチを示しています。

このレビューでは、チュートリアルをステップバイステップで実践した私の体験を共有し、特に効果的だった点を強調し、改善すべき点をいくつか指摘し、実際のプロジェクトに活かせる実用的な教訓を提供します。ビジネスアナリスト、プロダクトオーナー、開発者など、誰であっても、曖昧な要件を実行可能なモデルに変換する繰り返し可能なパターンをこのワークフローから得られます。
問題の理解:サトゥルン・インターナショナルの駐車場セキュリティシステム
ツールの使用に移る前に、シナリオを簡単に復習しましょう。サトゥルン・インターナショナルは、従業員用の本人確認カードを発行することで、従業員専用駐車場をセキュリティ化したいと考えています。システムは以下の機能を備える必要があります:
-
入口のバリケードで従業員およびゲストのカードを検証する
-
検証が成功した際に、自動的にバリケードを上げる
-
空きスペースがなくなった場合に「満車」の表示を出す
-
受付を通じて発行されたゲストカードを、返却ポリシーとともに管理する
これは物理的・デジタルの統合を伴うクラシックなアクセス制御問題であり、オブジェクト指向モデリングに最適なテーマです。
💡 プロのヒント:問題を自分の言葉で要約することから始めましょう。これにより明確さが求められ、初期段階でエッジケースを特定するのに役立ちます。
ステップ1:Visual Paradigmでのテキスト解析のセットアップ
このチュートリアルは、新しいプロジェクトとテキスト解析図の作成から始まります。流れは以下の通りです:
-
以下に移動します:プロジェクト > 新規作成、プロジェクト名を入力してください:チュートリアル、そして以下を選択してください:空のプロジェクトを作成
-
次に、以下に移動します:図 > 新規作成、次に以下を選択してください:テキスト解析、そして名前を付けてくださいセキュリティの向上
-
問題の詳細をすべてエディタに貼り付けてください
私の体験:インターフェースは直感的で、エディタは標準のクリップボード操作(Ctrl-V)をサポートしています。小さな提案ですが、ツールバーに「クリップボードから貼り付け」ボタンを直接追加すると、新規ユーザーの使いやすさが向上します。
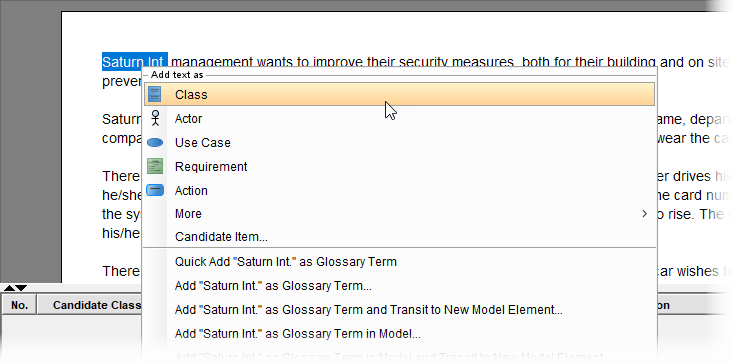
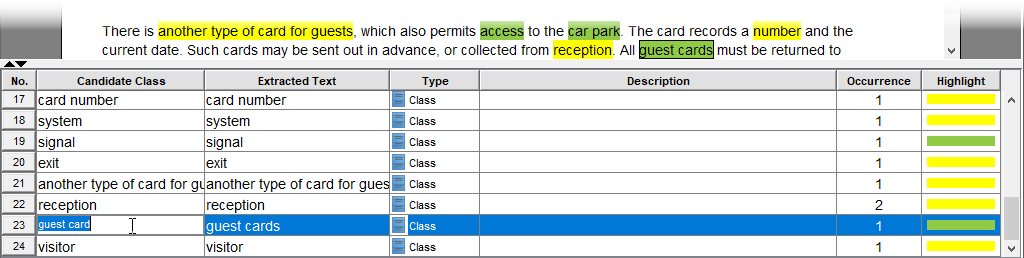
ステップ2:自然言語から候補クラスを特定する
テキストを読み込んだ後、次の段階は潜在的なクラスを抽出することです。チュートリアルはユーザーに次のように指示しています:
-
説明を丁寧に読み直してください
-
意味のある名詞句を右クリックしてください
-
選択してくださいテキストをクラスとして追加コンテキストメニューから

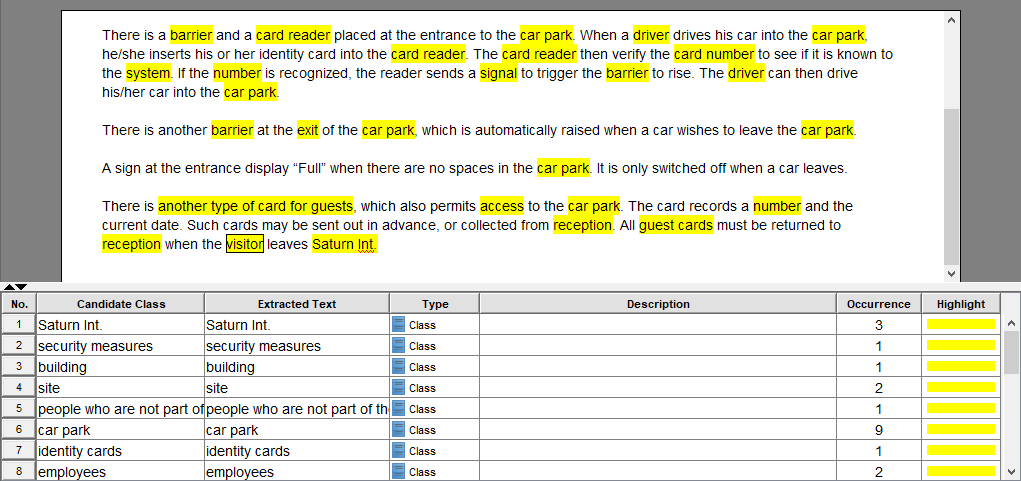
これにより、23の候補クラスの初期リストが生成され、以下が含まれます:
-
駐車場,身分証明カード,障壁,カードリーダー -
名前,部署,番号(後に属性として識別される) -
ドライバー,訪問者,会社のスタッフ(後に役割として特定)
気に入った点: 視覚的な強調により、進捗を簡単に追跡できます。テキストをインラインで選択できる機能—コンテキストを切り替えることなく—により、ワークフローがスムーズに保たれます。
ステップ3:拒否ルールを用いたクラスの絞り込みと精査
すべての名詞がクラスになる資格を持つわけではありません。チュートリアルでは7つの拒否基準を紹介します:
| ルール | 適用するタイミング |
|---|---|
| 重複 | 同じ概念に対して複数の用語がある |
| 関係ない | システムの範囲外 |
| 曖昧 | 明確な意味を持たない |
| 一般的 | 有用性を発揮するにはあまりに広すぎる |
| 属性 | 他のオブジェクトのプロパティ |
| 関連 | 実体ではなく関係 |
| 役割 | コアタイプではなく文脈的な識別子 |
これらのルールを適用することで、リストは23から7つの承認されたクラスにまで絞り込まれました:
| 候補 | 意思決定 | 理由 |
|---|---|---|
駐車場 |
✅ 受理 | コアシステムエンティティ |
身分証明書 |
✅ 受理 →スタッフカード | 明確さのために精練された |
アクセス |
✅ 受理 | 許可イベントを表す |
障壁 |
✅ 受理 | 物理的制御ポイント |
カードリーダー |
✅ 受理 | 入力/検証デバイス |
信号 |
✅ 受理 | システムトリガーメカニズム |
ゲストカード |
✅ 受理 →ゲストカード | 単数形の一貫性 |
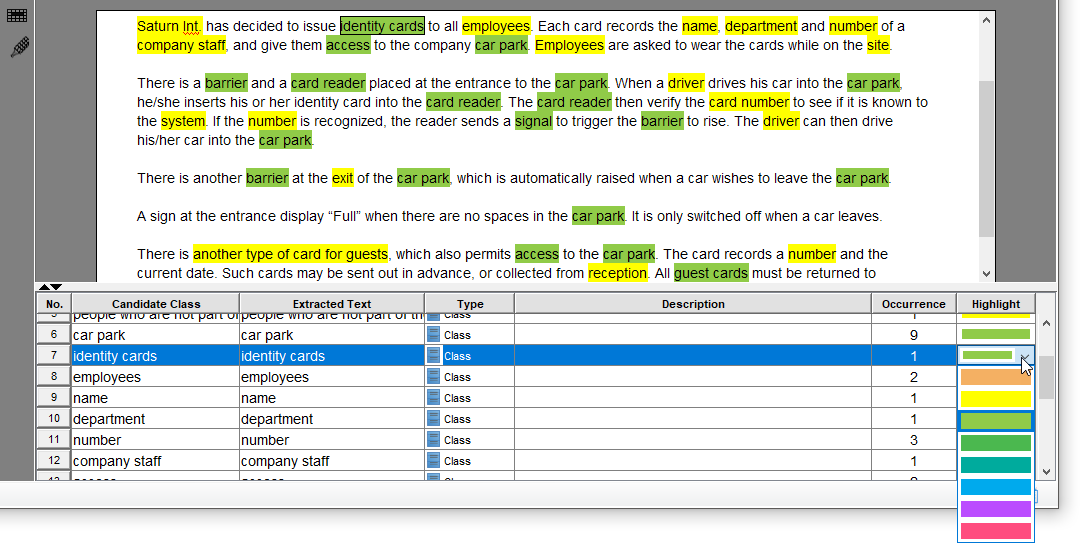
重要な洞察:このフィルタリングステップこそ、ドメイン専門知識が最も重要となる場所です。チュートリアルが単にルールを列挙するのではなく、文脈に応じてそれらをどう適用するかを示している点が、非常にありがたかったです。どのようにそれらを文脈に応じて適用する方法を。たとえば、ドライバー「役割」としてではなくクラスとして扱わないことで、不要な複雑さを回避できました。
ステップ4:クラス名の言い換えと標準化
モデル作成において一貫性が重要です。チュートリアルは次のように勧めています:
-
単数名詞の使用(
ゲストカードではなくゲストカード) -
曖昧な用語の明確化(
スタッフカード一般的なものではなく身分証カード)
| 元の内容 | 再表現 | 根拠 |
|---|---|---|
身分証カード |
スタッフカード |
従業員の文脈に特化 |
ゲストカード |
ゲストカード |
単数形の整合性 |
プロの技:私は個人的な規則を追加しました。ハードウェア関連のクラスに HW_(例: HW_Barrier)という接頭辞を付けることで、物理的要素と論理的要素を区別するようにしました。この柔軟性をツールが非常にうまく対応しています。
ステップ5:テキストをクラスモデル要素に変換する
明確化されたクラス名をもとに、テキストの注釈を正式なモデル要素に変換する時です:
-
承認された7つのクラスを複数選択する(Ctrl+クリック)
-
右クリック → モデル要素の作成
-
選択: 新しい図の作成、名前を付ける: 駐車場システム
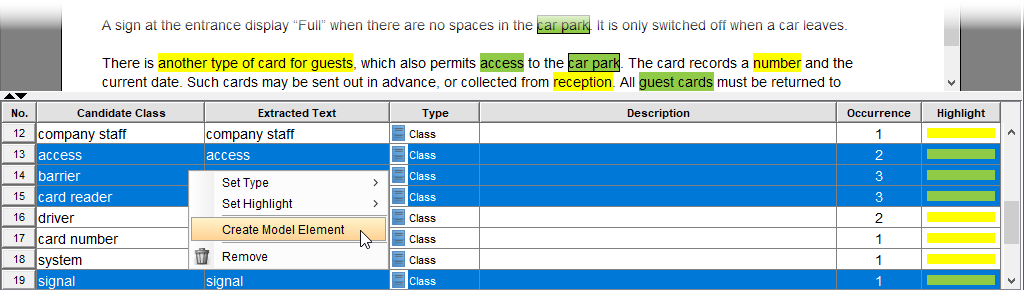
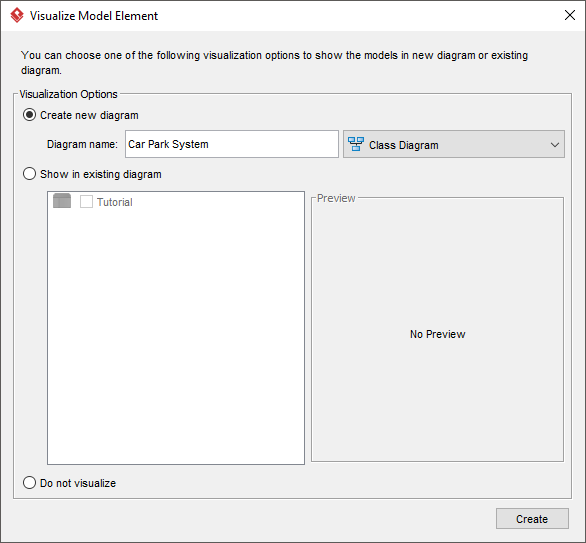
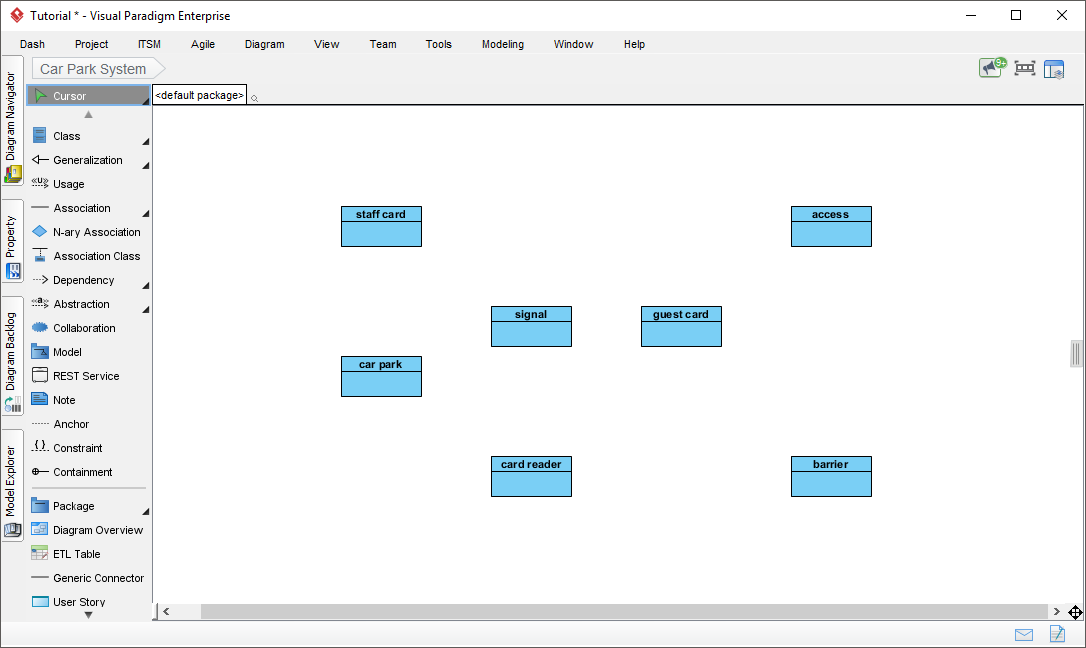
ワークフローウィン: 自動的な図の生成により、大幅な時間を節約できました。特に、ツールが私の命名規則を維持し、手動での再入力が不要だった点に価値を感じました。
ステップ6:クラス図における構造的関係の構築
クラスのリストは、関係が定義されるまではモデルとは言えません。チュートリアルでは、以下の追加を示しています:
-
一般化:
スタッフカードおよびゲストカードは抽象クラスから継承するカード -
関連:
カードリーダーは…とやり取りする障壁を通じて信号 -
依存:
駐車場に依存するアクセス容量追跡のための記録
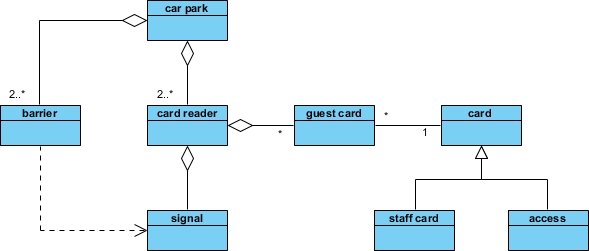
デザインの洞察: 抽象クラスである…の導入は、見事な一手でした。カードのスーパークラスの導入は、見事な一手でした。重複を減らし、モデルの拡張性を高めました。たとえば、…の追加などです。請負業者カード後で変更が必要になるのは最小限で済む。
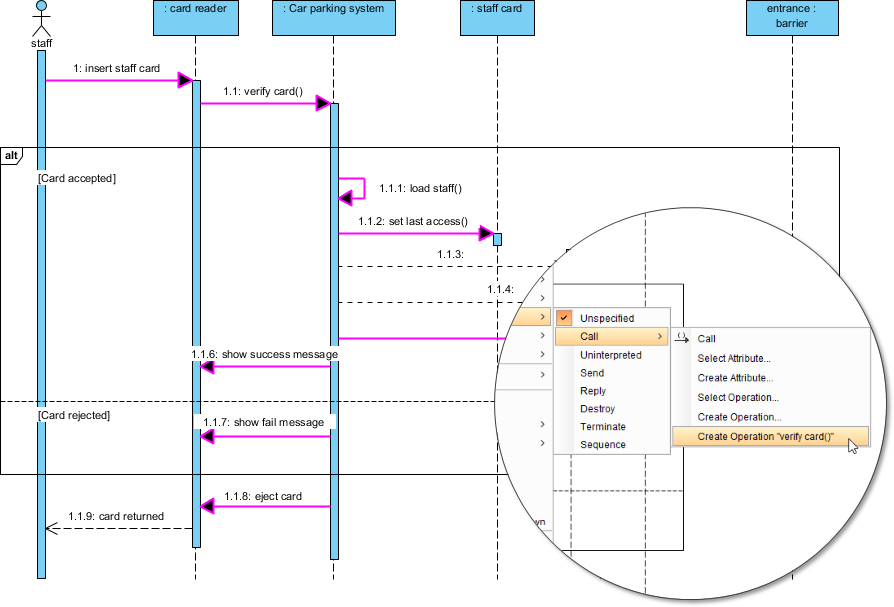
ステップ7:シーケンス図を用いた相互作用モデルの構築
静的構造は物語の半分しか語らない。動作をモデル化するため、「スタッフ入場」シナリオのシーケンス図を作成する:
-
図 > 新規作成 > シーケンス図 → 名前: 車両駐車(スタッフカード付き)
-
アクターを追加
スタッフおよびライフライン:カードリーダー,車両駐車システム、など -
メッセージフローをモデル化:
スタッフカードを挿入→カードを検証()→ 条件付き処理
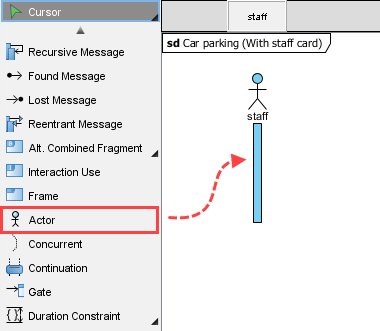
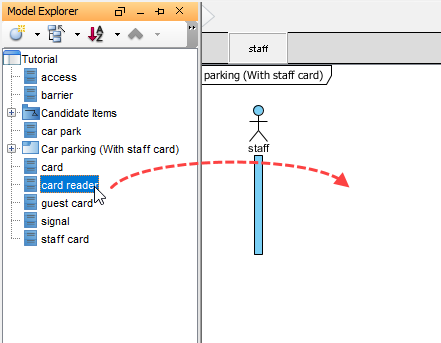
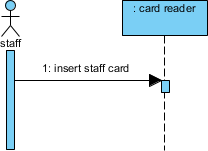
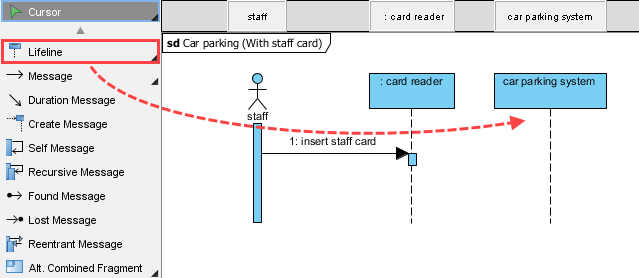
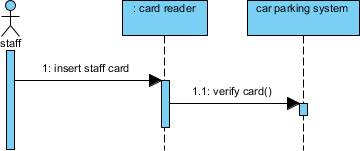
高度なテクニック: を使用して代替結合断片 (alt) を使用して成功/失敗のパスをモデル化する:
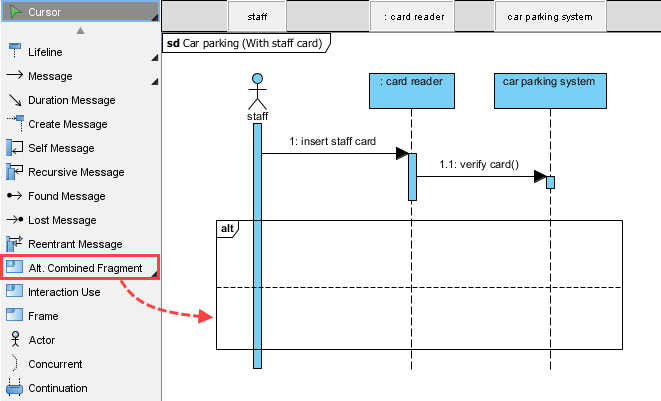
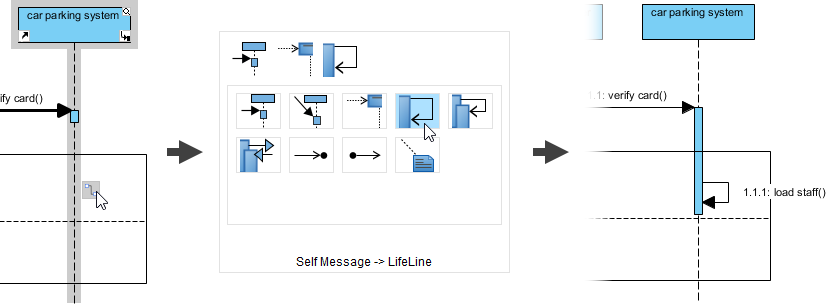
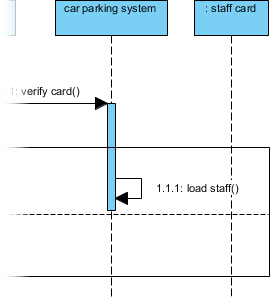
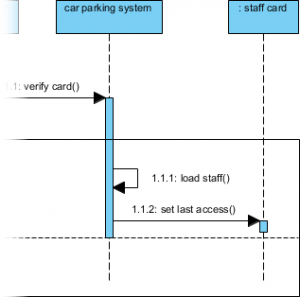
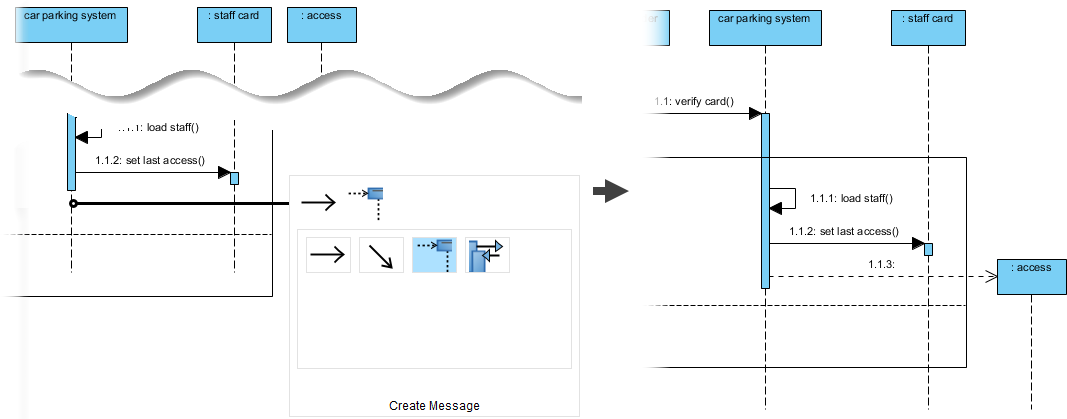
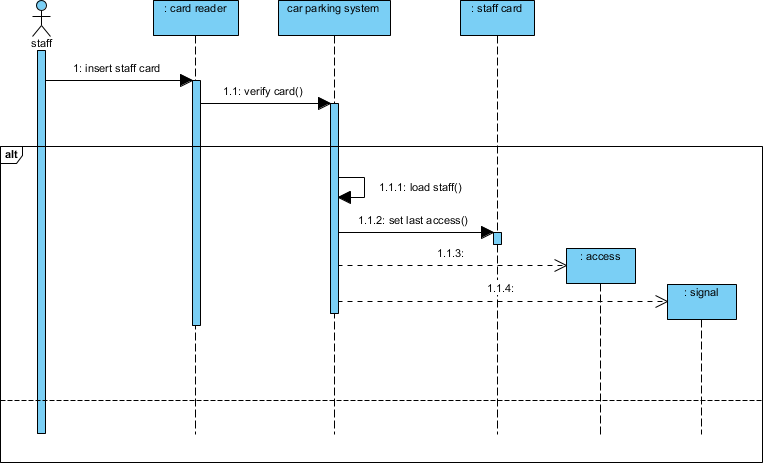
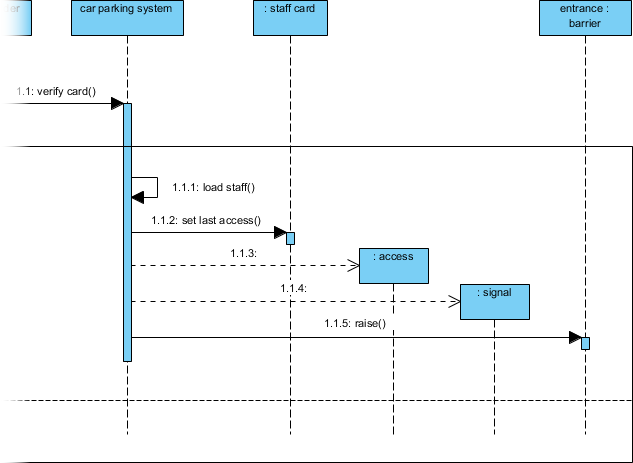
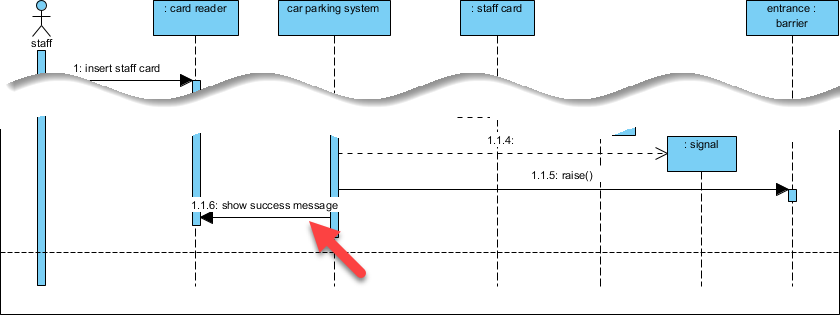
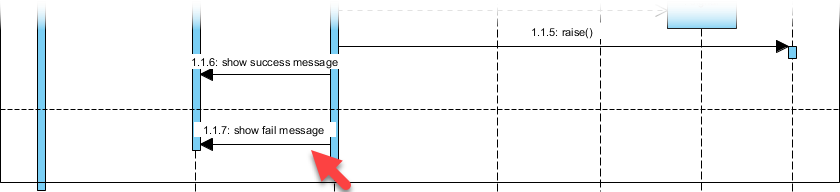
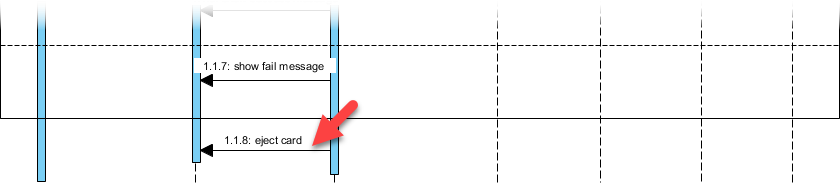
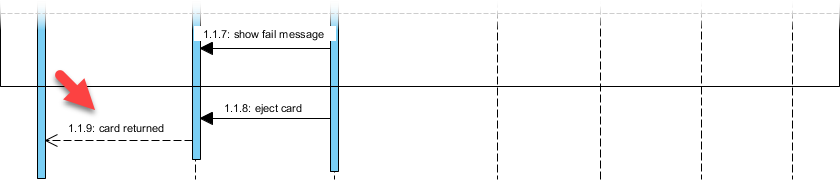
私の学び: alt断片を用いた条件付き論理の視覚的モデル化により、技術的でないステークホルダーにとって複雑なフローが直ちに理解可能になった。これは、クロスファンクショナルな調整において大きな成果である。alt 断片により、技術的でないステークホルダーにとって複雑なフローが直ちに理解可能になった。これは、クロスファンクショナルな調整において大きな成果である。
ステップ8:相互作用から操作と属性を抽出する
最終的な精査ステップでは、シーケンスメッセージをクラスの操作に変換する:
-
ライフラインを右クリック →クラス > クラスの作成「駐車場システム」
-
各メッセージについて、コネクタを右クリック →タイプ > 呼び出し > 操作の作成
クラス図に戻ると、自動入力された操作が表示されます:
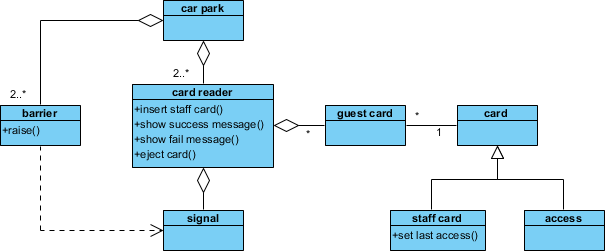
パワーフィーチャー: シーケンス図とクラス図の間で双方向同期が行われ、モデルの整合性が保たれます。一方のビューでメッセージ名を変更すると、すべての場所で自動的に更新されます。反復設計において時間を節約します。
私の体験:うまくいった点と改善すべき点
✅ 強み
-
ガイド付き発見: ステップバイステップのフィルタリングプロセスは、ツールの操作方法だけでなく、批判的思考を学ぶ機会を提供します
-
視覚的一貫性: 受理/拒否されたクラスに色分けすることで、認知負荷が軽減されました
-
モデル同期: 変更が図の間で自動的に伝播されます
-
現実的なシナリオ: 駐車場の例は、複雑さとアクセスのしやすさのバランスを取っています
⚠️ 改善すべき点
-
属性検出: ツールが属性(例:
カード番号,発行日)をクラス作成時に提案できるようにするべきです -
テンプレートライブラリ: IoT、医療、金融など一般的な分野向けの事前作成済みの拒否ルールテンプレートがあれば、オンボーディングが加速する
-
共同作業機能: 分散チーム向けのリアルタイム共同編集機能があれば、ワークフローが現代化される
🎯 プロジェクトへの実践的教訓
-
テキスト分析を早期に開始する「完璧な」要件を待つべきではない
-
ドメイン専門家を参加させるクラスのフィルタリング中に;彼らの直感がエッジケースを発見する
-
モデルを段階的に繰り返し改善する;一度に一つの順序図を処理することで、過負荷を防ぐ
-
拒否決定を文書化する;それらは将来のアーキテクトにとって貴重な根拠となる
結論:言葉を動作するシステムへと変換する
Visual Paradigmのテキスト分析チュートリアルは、ツールの操作方法を超えた価値を提供する。自然言語をクラス、関係、相互作用に体系的に変換するという、要件工学における厳密なマインドセットを教えている。チームは曖昧さを減らし、設計上の欠陥を早期に発見し、ビジネスの意図を真正に反映するモデルを構築できる。
ソフトウェアシステムがますます複雑化する中で、文章から構造を抽出する能力は単に便利なだけでなく、必須である。このワークフローは、深いドメイン分析やステークホルダーとの協働を置き換えるものではないが、それらを構築するための堅実な基盤を提供する。
車両駐車場のアクセスシステムをモデル化している場合でも、分散型マイクロサービスアーキテクチャを設計している場合でも、原則は同じである:注意深く聞き、仮定を問い直し、意図的にモデル化し、絶えず改善を繰り返す.
次のプロジェクトでこのアプローチを試してみてください。テキストがモデルを導くようにすることで、どれほど明確な理解が生まれるか、驚くかもしれません。