











L’analyse et la conception orientées objet (OOAD) restent le pilier de l’architecture logicielle moderne. Elle offre une approche structurée pour modéliser des systèmes où les données et les comportements sont encapsulés au sein d’objets. Toutefois, le chemin vers un système robuste est souvent semé de décisions architecturales subtiles qui peuvent se dégrader au fil du temps. Les développeurs tombent fréquemment dans des patterns qui semblent efficaces au départ mais engendrent un endettement technique important plus tard.
Ce guide explore les pièges spécifiques qui compromettent l’intégrité de la conception. En comprenant les symptômes et les causes de ces pièges, les équipes peuvent préserver leur flexibilité et réduire les coûts de maintenance. Nous examinerons les faiblesses structurelles qui mènent à des bases de code fragiles et comment structurer les systèmes pour assurer leur pérennité.
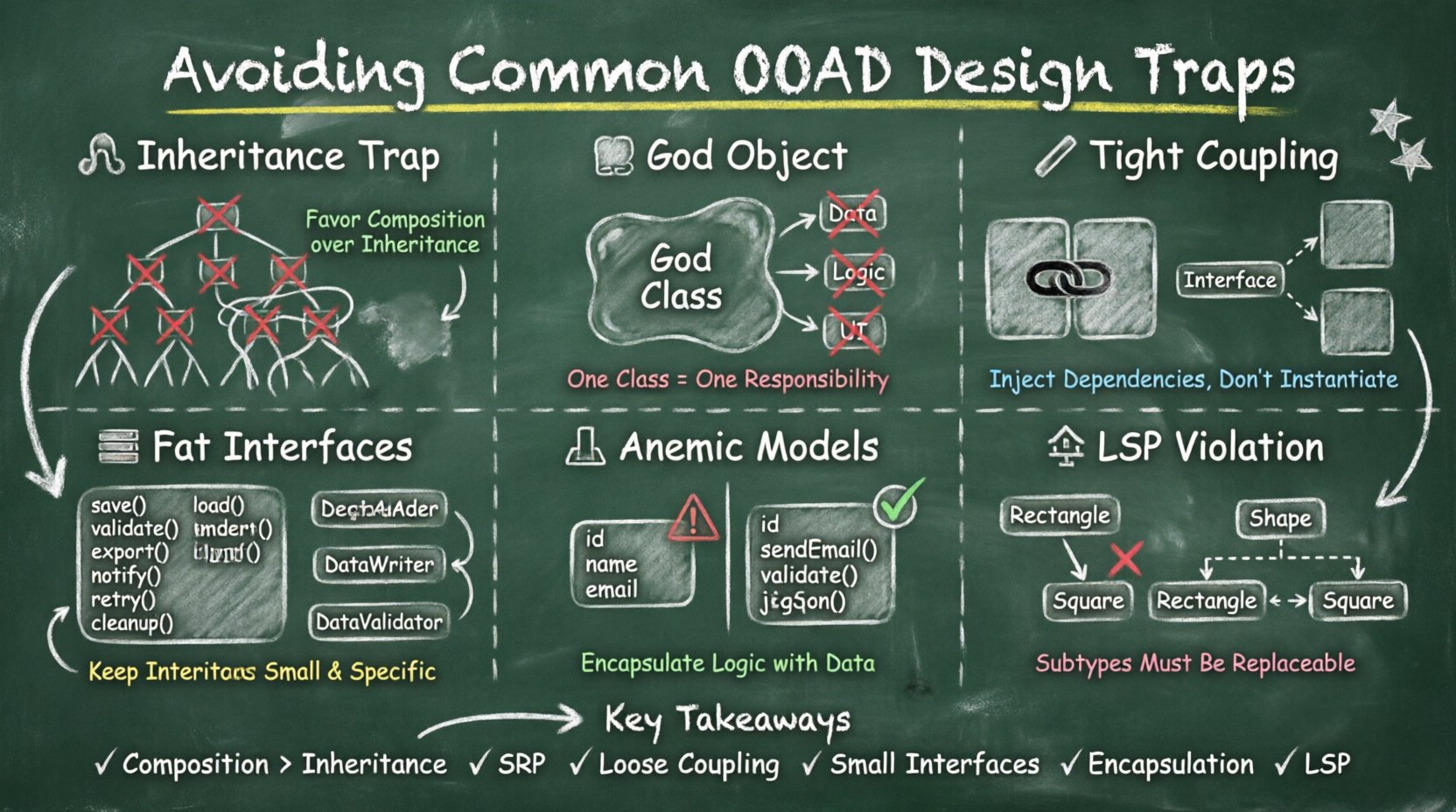
🧬 Le piège de l’héritage : les hiérarchies profondes
L’un des problèmes les plus répandus en OOAD est l’utilisation incorrecte de l’héritage. Bien que l’héritage permet la réutilisation du code et la polymorphisme, il crée une chaîne de dépendances rigide. Lorsque les développeurs s’appuient trop lourdement sur les hiérarchies de classes, ils se retrouvent souvent avec des arbres de classes profonds, difficiles à naviguer ou à modifier.
Pourquoi l’héritage devient un problème
- Classes de base fragiles : Un changement dans une classe de base peut briser la fonctionnalité de toutes les classes dérivées. Cela est connu sous le nom de problème de la classe de base fragile.
- Dépendances cachées : Les classes dérivées dépendent souvent des détails d’implémentation internes de leurs parents, qui devraient rester privés.
- Flexibilité limitée : L’héritage est une relation au moment de la compilation. Elle est statique et ne permet pas de modifier dynamiquement le comportement à l’exécution.
Reconnaître les symptômes
Si vous vous retrouvez à créer des classes uniquement pour partager du code sans relation claire « est un », vous utilisez probablement l’héritage de manière incorrecte. Recherchez :
- Des classes comprenant des centaines de lignes de code consacrées à la surcharge de méthodes.
- Une logique complexe répartie entre les classes parentes et les classes enfants.
- Des méthodes qui lancent des exceptions parce qu’elles ne sont pas applicables à une sous-classe spécifique.
Recommandation :Privilégiez la composition à l’héritage. Créez des objets qui contiennent d’autres objets. Cela permet de modifier dynamiquement le comportement sans modifier la hiérarchie des classes.
🏛️ Le anti-pattern de l’objet Dieu
Un « objet Dieu » est une classe qui sait trop ou fait trop. Elle agit généralement comme un hub central de l’application, gérant tout, de la récupération des données à la logique métier et au rendu de l’interface utilisateur. Bien que cela puisse simplifier le développement initial, cela crée un énorme goulot d’étranglement pour les tests et la maintenance.
Caractéristiques d’un objet Dieu
| Fonctionnalité | Impact sur le système |
|---|---|
| Taille | Souvent dépasse des centaines ou des milliers de lignes. |
| Couplage | Dépend de presque toutes les autres classes du système. |
| Responsabilité | Mélange l’accès aux données, la logique et la présentation. |
| Maintenabilité | Fort risque de régression lorsqu’il est modifié. |
Le coût des classes monolithiques
Lorsqu’une seule classe gère l’état de toute l’application, il devient impossible d’isoler les modifications. Si un bogue apparaît, il est difficile de retracer sa source. En outre, plusieurs développeurs travaillant sur le même fichier rencontreront constamment des conflits de fusion dans le contrôle de version.
Recommandation : Appliquez le principe de responsabilité unique (SRP). Assurez-vous que chaque classe a une seule raison de changer. Divisez les grandes classes en unités plus petites et ciblées. Utilisez l’injection de dépendances pour fournir les services nécessaires plutôt que de les créer internement.
🔗 Couplage étroit et gestion des dépendances
Le couplage fait référence au degré d’interdépendance entre les modules logiciels. Un couplage élevé signifie qu’une modification dans un module nécessite des modifications dans les autres. En OOAD, cela se manifeste souvent par des classes qui créent directement des instances de leurs dépendances.
Problèmes liés à l’instanciation directe
Lorsqu’une classe utilise newpour créer une dépendance, elle s’attache à une implémentation concrète spécifique. Cela empêche l’utilisation d’implémentations alternatives, telles que des mocks pour les tests ou des stratégies différentes selon les environnements.
- Difficulté de test :Les tests unitaires deviennent des tests d’intégration car vous ne pouvez pas facilement mocker la dépendance.
- Coût du restructurage :Changer la technologie sous-jacente nécessite des modifications importantes dans l’ensemble du code.
- Réutilisabilité :La classe ne peut pas être facilement déplacée vers un autre projet sans emporter ses dépendances.
Solutions pour un couplage faible
Pour atténuer ce problème, comptez sur les interfaces ou les classes abstraites. Définissez ce dont une classe a besoin plutôt que la manière dont elle l’obtient. Cela permet à la dépendance d’être injectée depuis l’extérieur. Cette approche est souvent appelée injection de dépendances.
- Utilisez les interfaces pour définir des contrats.
- Construisez des objets en passant leurs dépendances via les constructeurs ou les mutateurs.
- Gardez les détails d’implémentation cachés derrière des contrats publics.
📜 Ségrégation des interfaces et interfaces épaisses
Les interfaces sont censées définir des contrats. Toutefois, lorsque une interface devient trop grande, elle devient un fardeau. Cela est souvent appelé une violation du principe de ségrégation des interfaces. Les clients ne doivent pas être obligés de dépendre de méthodes qu’ils n’utilisent pas.
Le problème des interfaces épaisses
Imaginez une interface avec vingt méthodes. Une classe implémentant cette interface doit fournir les vingt méthodes, même si elle n’en utilise que deux. Cela entraîne :
- Implémentations vides :Méthodes qui lancent
NotImplementedExceptionou ne rien faire. - Confusion : Les développeurs ne peuvent pas déterminer quels méthodes sont pertinentes pour leur cas d’utilisation spécifique.
- Erreurs de compilation : Si l’interface change, toutes les implémentations doivent être mises à jour, même si le changement est sans rapport pour elles.
Meilleures pratiques pour les interfaces
Gardez les interfaces petites et ciblées. Regroupez les fonctionnalités liées dans des interfaces distinctes. Cela permet aux classes d’implémenter uniquement ce dont elles ont besoin. Cela rend également le système plus modulaire et plus facile à comprendre.
📊 Structures de données vs. Objets
Une confusion courante en OOAD est de traiter les objets comme de simples conteneurs de données. Bien que les objets encapsulent des données, ils doivent aussi encapsuler des comportements. Traiter les objets comme des structures de données conduit à des « modèles de domaine anémiques » où l’objet possède des champs publics mais aucune logique.
Le piège du modèle anémique
Lorsque les données et la logique sont séparées, vous aboutissez à des classes Service qui contiennent toutes les règles métier. Cela viole l’encapsulation. Les données deviennent vulnérables à des états incohérents car il n’y a pas de vérification d’invariants à l’intérieur de l’objet lui-même.
Meilleures pratiques pour l’encapsulation
- Rendez les champs privés et exposez l’état via des méthodes.
- Assurez-vous que les méthodes modifient l’état d’une manière qui maintient la validité de l’objet.
- Déplacez la logique qui appartient aux données à l’intérieur de l’objet lui-même.
En gardant les données et le comportement ensemble, vous réduisez la surface d’erreurs. L’objet lui-même devient le gardien de son intégrité propre.
🎯 Le principe de substitution de Liskov (LSP)
Le LSP stipule que les objets d’une superclasse doivent pouvoir être remplacés par des objets de leurs sous-classes sans casser l’application. Violation de ce principe entraîne un comportement imprévisible lors de l’utilisation de la polymorphisme.
Violations de sous-type
Considérez une classe carré héritant d’une classe rectangle. Si vous définissez la largeur, la hauteur doit rester identique. Si vous définissez la hauteur, la largeur doit rester identique. Un carré ne peut pas satisfaire cette contrainte. Par conséquent, un carré n’est pas un sous-type valide d’un rectangle dans ce contexte.
Ce type de désaccord sémantique brise les attentes du code utilisant l’objet. Il oblige le consommateur à vérifier le type spécifique avant de l’utiliser, ce qui contredit l’objectif de la polymorphisme.
Assurer la conformité au LSP
- Assurez-vous que les sous-classes ne renforcent pas les préconditions.
- Assurez-vous que les sous-classes ne affaiblissent pas les postconditions.
- Assurez-vous que les sous-classes ne modifient pas les invariants de la superclasse.
⚖️ Nuances du principe de responsabilité unique (SRP)
Le SRP est fréquemment mal compris comme « une classe, un travail ». En réalité, cela signifie « une seule raison de changer ». Une classe peut gérer plusieurs tâches, mais si ces tâches sont motivées par des parties prenantes différentes ou des exigences en évolution, elles doivent être séparées.
Identifier les responsabilités
Demandez-vous : « Qu’est-ce qui fait changer cette classe ? » Si la réponse est plusieurs facteurs distincts, la classe a plusieurs responsabilités. Les coupables fréquents incluent :
- Logique d’accès à la base de données mélangée aux règles métier.
- La logique de formatage mélangée à la logique de calcul.
- La logique de journalisation mélangée à la fonctionnalité principale.
Séparer ces préoccupations permet aux équipes de travailler en parallèle. Une équipe peut mettre à jour la couche de données sans affecter la couche de calcul.
🔄 Le piège de l’itérateur
Les itérateurs permettent de parcourir des collections. Cependant, les itérateurs personnalisés peuvent introduire de la complexité si ils ne sont pas correctement gérés. Exposer la structure interne d’une collection à travers un itérateur personnalisé lie le client à cette structure spécifique.
Quand utiliser les itérateurs standards
Sauf si vous avez un besoin spécifique de parcours personnalisé, comptez sur les itérateurs standards des collections. Ils sont bien testés et prévisibles. Créer un nouvel itérateur pour chaque type de collection ajoute du code boilerplate inutile et des risques de bogues.
🔒 L’encapsulation et la visibilité
L’encapsulation est le principe de masquer l’état interne. Cependant, une encapsulation excessive peut freiner le développement, tandis qu’une encapsulation insuffisante expose le système aux erreurs. Trouver l’équilibre est essentiel.
Modificateurs de visibilité
- Public : Utilisez avec parcimonie. Exposez uniquement ce qui est nécessaire pour le contrat.
- Protégé : Utilisez pour l’héritage, mais soyez conscient de la fragilité qu’il introduit.
- Privé : Préférez cela par défaut. Cacher les détails d’implémentation.
Ne rendez pas les méthodes publiques uniquement parce qu’elles sont pratiques. Si une méthode n’est pas partie du contrat public, gardez-la privée. Cela réduit la surface d’erreurs.
📈 Impact sur la dette technique
Chaque piège de conception évoqué ci-dessus contribue à la dette technique. La dette technique est le coût implicite d’un rework supplémentaire causé par le choix d’une solution facile maintenant au lieu d’une approche meilleure qui prendrait plus de temps.
Conséquences à long terme
- Vitesse de développement ralentie : Plus de temps est consacré à la correction des bogues qu’à l’ajout de fonctionnalités.
- Coûts d’intégration plus élevés : Les nouveaux développeurs peinent à comprendre les systèmes complexes et couplés.
- Risque de refactoring : La peur de casser la fonctionnalité existante empêche les améliorations nécessaires.
Investir du temps dans une conception propre rapporte des bénéfices tout au long du cycle de vie du logiciel. Cela réduit la charge cognitive sur l’équipe et rend le système plus adaptable aux changements.
🛡️ Résumé de la stabilité de la conception
Construire un logiciel robuste exige de la vigilance. Les pièges décrits dans ce guide sont fréquents car ils offrent une commodité à court terme. Toutefois, le coût à long terme est élevé. En privilégiant le découplage lâche, la forte cohésion et le respect des principes établis, les équipes peuvent créer des systèmes durables.
Souvenez-vous que la conception n’est pas une activité ponctuelle. C’est un processus itératif. Revoyez continuellement votre architecture à la lumière de ces critères. Refactorez lorsque nécessaire. N’acceptez pas que l’état « code fonctionnel » éclipse l’objectif de « code maintenable ».
📝 Points clés pour la conception orientée objet
- Évitez l’héritage profond :Utilisez la composition pour obtenir une réutilisation.
- Évitez les objets-Dieu :Gardez les classes centrées sur une seule responsabilité.
- Gérez les dépendances :Injectez les dépendances plutôt que de les créer.
- Simplifiez les interfaces :Gardez-les petites et spécifiques.
- Protégez l’état :Encapsulez les données et imposez les invariants.
- Respectez le principe de substitution de Liskov (LSP) :Assurez que les sous-classes peuvent remplacer les classes parentes sans heurt.
Adopter ces pratiques exige de la discipline. Il est plus facile d’écrire un script rapide que de concevoir un système. Mais la différence entre un prototype et un produit réside souvent dans la qualité de la conception sous-jacente. Restez attentif à la structure, et votre logiciel servira efficacement sa fonction pendant de nombreuses années.