











Die objektorientierte Analyse und Entwicklung (OOAD) bleibt die Grundlage der modernen Softwarearchitektur. Sie bietet einen strukturierten Ansatz zur Modellierung von Systemen, bei denen Daten und Verhalten innerhalb von Objekten gekapselt sind. Doch der Weg zu einem robusten System ist oft mit subtilen architektonischen Entscheidungen gepflastert, die sich im Laufe der Zeit verschlechtern können. Entwickler geraten häufig in Muster, die anfangs effizient erscheinen, aber später erhebliche technische Schulden verursachen.
Diese Anleitung untersucht die spezifischen Fallen, die die Integrität des Designs beeinträchtigen. Durch das Verständnis der Symptome und Ursachen dieser Fallen können Teams Flexibilität bewahren und Wartungskosten senken. Wir werden die strukturellen Schwächen untersuchen, die zu brüchigen Codebasen führen, und wie man Systeme für Langlebigkeit aufbaut.
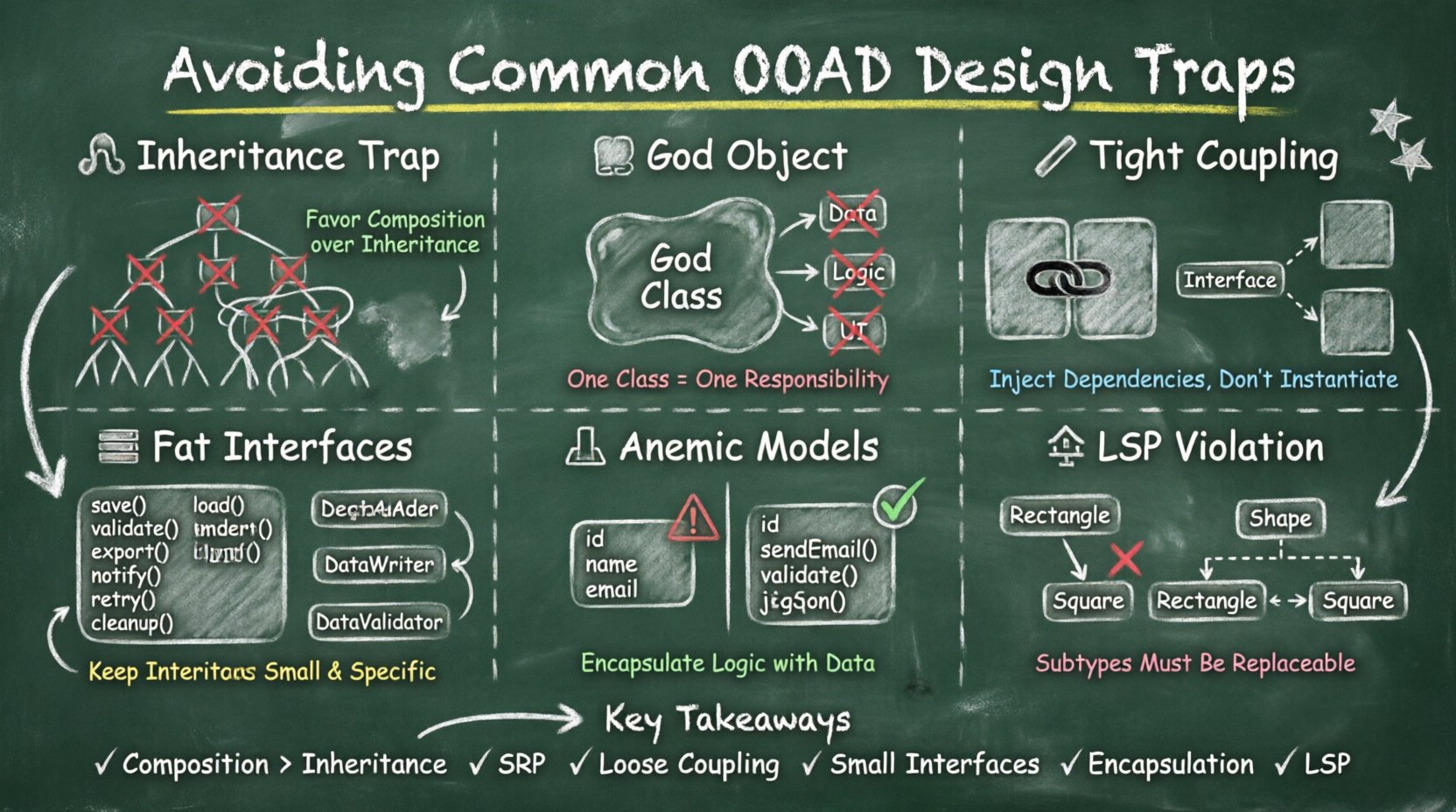
🧬 Die Vererbungsfalle: Tiefgehende Hierarchien
Eine der verbreitetsten Probleme in der OOAD ist die Missbrauch der Vererbung. Während die Vererbung Code-Wiederverwendung und Polymorphie ermöglicht, schafft sie eine starre Abhängigkeitskette. Wenn Entwickler zu stark auf Klassenhierarchien setzen, enden sie oft mit tiefen Baumstrukturen aus Klassen, die schwer zu durchschauen oder zu ändern sind.
Warum die Vererbung zu einem Problem wird
- Brüchige Basisklassen: Eine Änderung in einer Basisklasse kann die Funktionalität in jeder abgeleiteten Klasse stören. Dies wird als das Problem der brüchigen Basisklasse bezeichnet.
- Verborgene Abhängigkeiten: Abgeleitete Klassen verlassen sich oft auf interne Implementierungsdetails ihrer Elternklassen, die privat bleiben sollten.
- Begrenzte Flexibilität: Die Vererbung ist eine Kompilationszeit-Beziehung. Sie ist statisch und erlaubt keine dynamischen Änderungen des Verhaltens zur Laufzeit.
Erkennen der Symptome
Wenn Sie feststellen, dass Sie Klassen erstellen, nur um Code zu teilen, ohne eine klare „ist-ein“-Beziehung, dann nutzen Sie die Vererbung wahrscheinlich falsch. Achten Sie auf:
- Klassen mit Hunderten von Codezeilen, die ausschließlich der Überschreibung von Methoden gewidmet sind.
- Komplexe Logik, die über Eltern- und Kindklassen verteilt ist.
- Methoden, die Ausnahmen werfen, weil sie für eine bestimmte Unterklasse nicht anwendbar sind.
Empfehlung: Verwenden Sie Zusammensetzung statt Vererbung. Erstellen Sie Objekte, die andere Objekte enthalten. Dadurch kann das Verhalten dynamisch ausgetauscht werden, ohne die Klassenhierarchie zu verändern.
🏛️ Das Anti-Muster des Götter-Objekts
Ein „Götter-Objekt“ ist eine Klasse, die zu viel weiß oder zu viel tut. Es fungiert typischerweise als zentraler Knotenpunkt der Anwendung und übernimmt alles von der Datenabrufung über Geschäftslogik bis hin zur Benutzeroberflächen-Rendering. Obwohl dies die anfängliche Entwicklung vereinfachen kann, schafft es eine massive Engstelle für Tests und Wartung.
Eigenschaften eines Götter-Objekts
| Merkmale | Auswirkung auf das System |
|---|---|
| Größe | Übersteigt oft Hunderte oder Tausende von Zeilen. |
| Kopplung | Hängt von fast jeder anderen Klasse im System ab. |
| Verantwortung | Vermischt Datenzugriff, Logik und Darstellung. |
| Wartbarkeit | Hohe Gefahr von Regressionen bei Änderungen. |
Die Kosten monolithischer Klassen
Wenn eine einzelne Klasse den Zustand der gesamten Anwendung verwaltet, wird es unmöglich, Änderungen zu isolieren. Wenn ein Fehler auftritt, ist es schwierig, die Quelle zu verfolgen. Außerdem werden mehrere Entwickler, die an derselben Datei arbeiten, ständige Merge-Konflikte im Versionskontrollsystem erleben.
Empfehlung: Wenden Sie das Single Responsibility Principle (SRP) an. Stellen Sie sicher, dass jede Klasse nur einen Grund zur Änderung hat. Teilen Sie große Klassen in kleinere, fokussierte Einheiten auf. Verwenden Sie Abhängigkeitsinjektion, um notwendige Dienste bereitzustellen, anstatt sie intern zu erstellen.
🔗 Starke Kopplung und Abhängigkeitsverwaltung
Kopplung bezieht sich auf das Maß an Wechselwirkung zwischen Softwaremodulen. Hohe Kopplung bedeutet, dass eine Änderung in einem Modul Änderungen in anderen Modulen erfordert. In OOAD zeigt sich dies oft darin, dass Klassen Instanzen ihrer Abhängigkeiten direkt erstellen.
Probleme bei direkter Instanziierung
Wenn eine Klasse verwendetnewum eine Abhängigkeit zu erstellen, bindet sie sich an eine bestimmte konkrete Implementierung. Dies verhindert die Verwendung alternativer Implementierungen, wie z. B. Mocks für Tests oder verschiedene Strategien für unterschiedliche Umgebungen.
- Testschwierigkeiten: Einheitstests werden Integrationstests, weil Sie die Abhängigkeit nicht leicht mocken können.
- Refaktorisierungskosten: Die Änderung der zugrundeliegenden Technologie erfordert umfassende Änderungen im gesamten Codebase.
- Wiederverwendbarkeit: Die Klasse kann nicht leicht in ein anderes Projekt verschoben werden, ohne ihre Abhängigkeiten mitzunehmen.
Lösungen für lose Kopplung
Um dies zu mindern, setzen Sie auf Schnittstellen oder abstrakte Klassen. Definieren Sie, was eine Klasse benötigt, anstatt wie sie es erhält. Dadurch kann die Abhängigkeit von außen injiziert werden. Dieser Ansatz wird oft Abhängigkeitsinjektion genannt.
- Verwenden Sie Schnittstellen, um Verträge zu definieren.
- Erstellen Sie Objekte mit ihren Abhängigkeiten, die über Konstruktoren oder Setter übergeben werden.
- Halten Sie Implementierungsdetails hinter öffentlichen Verträgen versteckt.
📜 Schnittstellen-Segregation und fette Schnittstellen
Schnittstellen sollen Verträge definieren. Wenn eine Schnittstelle jedoch zu groß wird, wird sie jedoch zur Belastung. Dies wird oft als Verletzung des Prinzips der Schnittstellen-Segregation bezeichnet. Clients sollten nicht gezwungen werden, auf Methoden zu verweisen, die sie nicht verwenden.
Das Problem der fettigen Schnittstelle
Stellen Sie sich eine Schnittstelle mit zwanzig Methoden vor. Eine Klasse, die diese Schnittstelle implementiert, muss alle zwanzig bereitstellen, auch wenn sie nur zwei verwendet. Dies führt zu:
- Leere Implementierungen: Methoden, die werfen
NotImplementedExceptionoder tun Sie nichts. - Verwirrung: Entwickler können nicht sagen, welche Methoden für ihren spezifischen Anwendungsfall relevant sind.
- Kompilierungsfehler: Wenn die Schnittstelle geändert wird, müssen alle Implementierungen aktualisiert werden, auch wenn die Änderung für sie irrelevant ist.
Best Practices für Schnittstellen
Halten Sie Schnittstellen klein und fokussiert. Gruppieren Sie verwandte Funktionalitäten in getrennten Schnittstellen. Dadurch können Klassen nur das implementieren, was sie benötigen. Außerdem macht dies das System modularer und verständlicher.
📊 Datenstrukturen vs. Objekte
Ein häufiger Irrtum in OOAD ist, Objekte als bloße Datenträger zu betrachten. Obwohl Objekte Daten kapseln, sollten sie auch Verhalten kapseln. Objekte als Datenstrukturen zu behandeln führt zu „anämischen Domänenmodellen“, bei denen das Objekt öffentliche Felder, aber keine Logik besitzt.
Die Falle des anämischen Modells
Wenn Daten und Logik getrennt werden, endet man bei Service-Klassen, die alle Geschäftsregeln enthalten. Dies verstößt gegen die Kapselung. Die Daten werden anfällig für inkonsistente Zustände, da innerhalb des Objekts selbst keine Invarianz gewährleistet wird.
Best Practices zur Kapselung
- Machen Sie Felder privat und stellen Sie den Zustand über Methoden zur Verfügung.
- Stellen Sie sicher, dass Methoden den Zustand so ändern, dass die Gültigkeit des Objekts erhalten bleibt.
- Verschieben Sie die Logik, die zur Datenstruktur gehört, in das Objekt selbst.
Durch die Zusammenführung von Daten und Verhalten reduzieren Sie die Angriffsfläche für Fehler. Das Objekt selbst wird zum Hüter seiner eigenen Integrität.
🎯 Das Liskov-Substitutionsprinzip (LSP)
Das LSP besagt, dass Objekte einer Oberklasse durch Objekte ihrer Unterklassen ersetzt werden können, ohne die Anwendung zu beschädigen. Die Verletzung dieses Prinzips führt zu unvorhersehbarem Verhalten, wenn Polymorphie verwendet wird.
Untertypverletzungen
Betrachten Sie eine Quadrat-Klasse, die von einer Rechteck-Klasse erbt. Wenn Sie die Breite festlegen, muss die Höhe gleich bleiben. Wenn Sie die Höhe festlegen, muss die Breite gleich bleiben. Ein Quadrat kann diese Einschränkung nicht erfüllen. Daher ist ein Quadrat in diesem Kontext kein gültiger Untertyp eines Rechtecks.
Ein solcher semantischer Missstand bricht die Erwartungen des Codes, der das Objekt verwendet. Er zwingt den Nutzer, vor der Verwendung den spezifischen Typ zu prüfen, was den Zweck der Polymorphie zunichtemacht.
Sicherstellen der LSP-Konformität
- Stellen Sie sicher, dass Unterklassen keine Voraussetzungen verschärfen.
- Stellen Sie sicher, dass Unterklassen keine Nachbedingungen schwächen.
- Stellen Sie sicher, dass Unterklassen die Invarianten der Oberklasse nicht ändern.
⚖️ Nuancen des Single-Responsibility-Prinzips (SRP)
Das SRP wird häufig missverstanden als „eine Klasse, eine Aufgabe“. Tatsächlich bedeutet es „eine Ursache für eine Änderung“. Eine Klasse kann mehrere Aufgaben erfüllen, aber wenn diese Aufgaben von unterschiedlichen Stakeholdern oder sich ändernden Anforderungen getrieben werden, sollten sie getrennt werden.
Verantwortlichkeiten identifizieren
Fragen Sie sich: „Was verursacht eine Änderung dieser Klasse?“ Wenn die Antwort mehrere unterschiedliche Faktoren ist, hat die Klasse mehrere Verantwortlichkeiten. Häufige Ursachen sind:
- Datenbankzugriffslogik, die mit Geschäftsregeln vermischt ist.
- Formatierungslogik vermischt mit Berechnungslogik.
- Protokollierungslogik vermischt mit Kernfunktionalität.
Die Trennung dieser Aspekte ermöglicht es Teams, parallel zu arbeiten. Ein Team kann die Datenebene aktualisieren, ohne die Berechnungsebene zu beeinflussen.
🔄 Die Iterator-Falle
Iterator ermöglichen die Durchquerung von Sammlungen. Allerdings können benutzerdefinierte Iterator Komplexität einführen, wenn sie nicht korrekt verwaltet werden. Die Exposition der internen Struktur einer Sammlung über einen benutzerdefinierten Iterator koppelt den Client an diese spezifische Struktur.
Wann man Standard-Iterator verwenden sollte
Sofern Sie keinen spezifischen Bedarf an benutzerdefiniertem Durchlaufen haben, verlassen Sie sich auf Standard-Iterator für Sammlungen. Sie sind gut getestet und vorhersehbar. Die Erstellung eines neuen Iterators für jede Sammlungstyp führt zu unnötigem Boilerplate und potenziellen Fehlern.
🔒 Kapselung und Sichtbarkeit
Kapselung ist das Prinzip, den internen Zustand zu verbergen. Allerdings kann übermäßige Kapselung die Entwicklung behindern, während zu geringe Kapselung das System Fehlern aussetzt. Die richtige Balance zu finden, ist entscheidend.
Sichtbarkeitsmodifizierer
- Öffentlich: Verwenden Sie sparsam. Exponieren Sie nur das, was für den Vertrag notwendig ist.
- Geschützt: Verwenden Sie für Vererbung, aber seien Sie sich der Fragilität bewusst, die es mit sich bringt.
- Privat: Gehen Sie davon aus. Verbergen Sie Implementierungsdetails.
Machen Sie Methoden nicht einfach nur wegen ihrer Bequemlichkeit öffentlich. Wenn eine Methode nicht Teil des öffentlichen Vertrags ist, halten Sie sie privat. Dadurch wird die Fläche für Fehler reduziert.
📈 Auswirkung auf technische Schulden
Jede oben besprochene Design-Falle trägt zur technischen Schuld bei. Technische Schuld ist die implizierte Kosten für zusätzliche Umarbeitung, die entsteht, wenn man jetzt eine einfache Lösung wählt, anstatt eine bessere, aber längere Lösung zu verwenden.
Langfristige Konsequenzen
- Langsamere Entwicklungs-Geschwindigkeit: Es wird mehr Zeit dafür aufgewendet, Fehler zu beheben, als neue Funktionen hinzuzufügen.
- Höhere Einarbeitungskosten: Neue Entwickler kämpfen damit, komplexe, verflochtene Systeme zu verstehen.
- Refactoring-Risiko: Die Angst, bestehende Funktionalität zu beschädigen, verhindert notwendige Verbesserungen.
Die Investition von Zeit in eine saubere Gestaltung zahlt sich über die Lebensdauer der Software aus. Sie verringert die kognitive Belastung für das Team und macht das System anpassungsfähiger an Veränderungen.
🛡️ Zusammenfassung der Design-Stabilität
Der Aufbau robuster Software erfordert Aufmerksamkeit. Die in diesem Leitfaden beschriebenen Fallen sind verbreitet, weil sie kurzfristige Bequemlichkeit bieten. Die langfristigen Kosten sind jedoch hoch. Durch die Priorisierung von lose gekoppelten Systemen, hoher Kohäsion und Einhaltung etablierter Prinzipien können Teams Systeme schaffen, die Bestand haben.
Denken Sie daran, dass Design keine einmalige Tätigkeit ist. Es ist ein iterativer Prozess. Überprüfen Sie Ihre Architektur kontinuierlich anhand dieser Kriterien. Refaktorisieren Sie, wenn nötig. Lassen Sie sich nicht von der Haltung „funktionsfähiger Code“ über die Zielsetzung „pflegbarer Code“ hinwegtäuschen.
📝 Wichtige Erkenntnisse für OOAD
- Vermeide tiefe Vererbung:Verwende Zusammensetzung, um Wiederverwendung zu erreichen.
- Vermeide Götterobjekte:Halte Klassen auf eine einzige Verantwortung fokussiert.
- Verwalte Abhängigkeiten:Injiziere Abhängigkeiten statt sie zu erstellen.
- Vereinfache Schnittstellen:Halte sie klein und spezifisch.
- Schütze den Zustand:Kapsle Daten und stelle Invarianten sicher.
- Respektiere das LSP:Stelle sicher, dass Unterklassen Elternklassen nahtlos ersetzen können.
Die Einführung dieser Praktiken erfordert Disziplin. Es ist einfacher, ein schnelles Skript zu schreiben, als ein System zu entwerfen. Doch der Unterschied zwischen einem Prototypen und einem Produkt liegt oft in der Qualität des zugrundeliegenden Designs. Bleibe bewusst bezüglich der Struktur, und deine Software wird ihre Aufgabe jahrelang zuverlässig erfüllen.