











Dans le paysage du développement logiciel, l’intégrité structurelle d’une application détermine sa durée de vie. Lorsque les composants sont étroitement entrelacés, un petit changement dans une zone peut provoquer des défaillances en chaîne ailleurs. C’est là tout l’essence de l’agrégation. Pour les architectes et les développeurs, concevoir un système avec une agrégation détachée n’est pas simplement un choix ; c’est une nécessité pour une croissance durable. Ce guide explore comment utiliser efficacement les diagrammes de paquets pour minimiser les dépendances et maximiser la flexibilité. 🛡️
Comprendre l’agrégation dans l’architecture logicielle 🔗
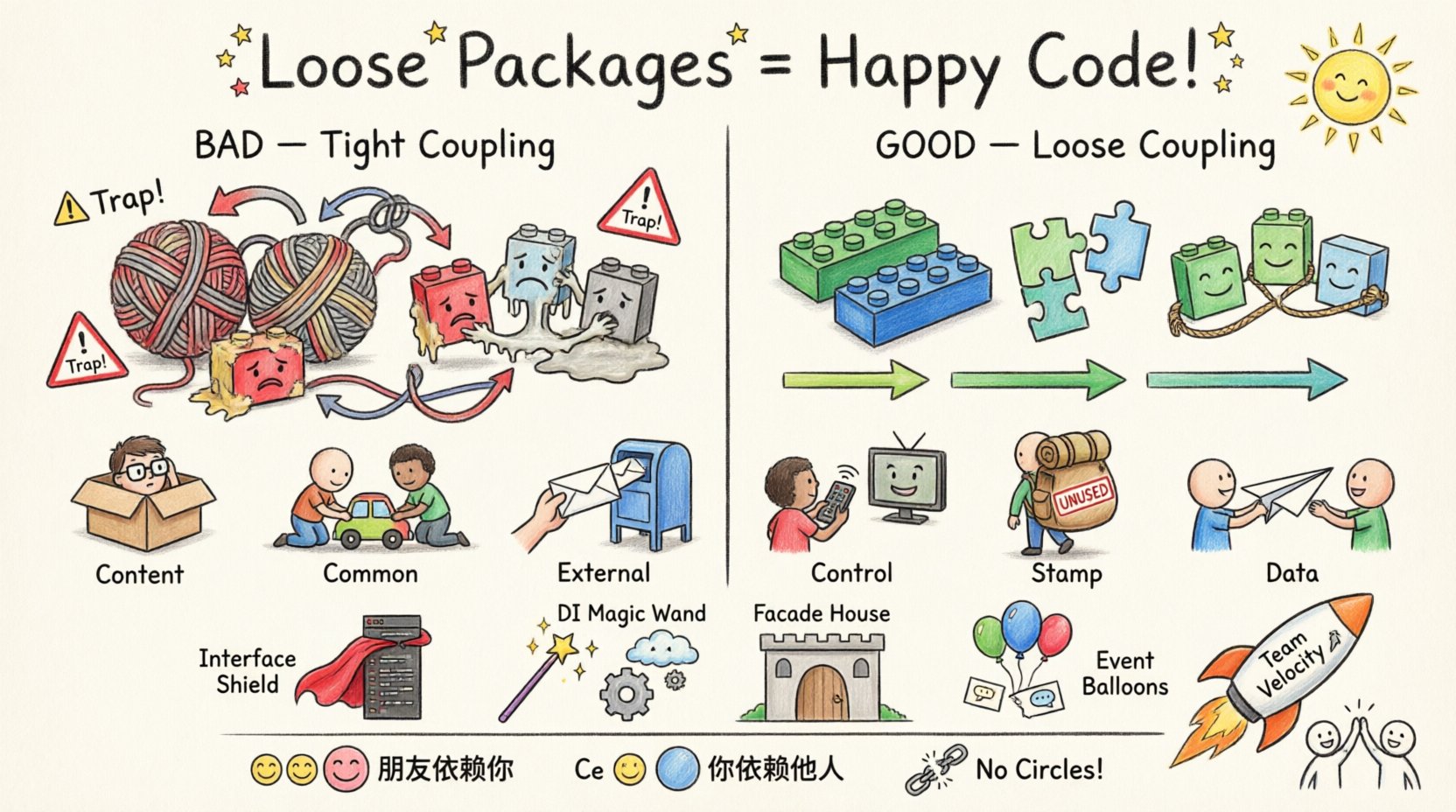
L’agrégation décrit le degré d’interdépendance entre les modules logiciels. Elle mesure à quel point deux routines ou modules sont étroitement liés. Lorsque l’agrégation est élevée, les modules dépendent fortement des détails d’implémentation internes d’autres modules. Cela crée un système fragile où les modifications nécessitent un refactoring important. À l’inverse, une faible agrégation implique que les modules interagissent à travers des interfaces bien définies, protégeant la logique interne des influences externes.
Pourquoi cette distinction est-elle importante ? Pensez à un scénario où un module doit communiquer avec une base de données. Si celui-ci se connecte directement au pilote de base de données, il est fortement agrégé. Si la communication s’effectue par une couche d’abstraction, il est faiblement agrégé. Ce dernier permet de changer de technologie de base de données sans réécrire la logique métier.
Types d’agrégation
Toute agrégation n’est pas équivalente. Comprendre le spectre aide à identifier les interactions à minimiser.
- Agrégation de contenu : Un module modifie directement ou dépend des données internes d’un autre. Il s’agit de la forme la plus forte d’agrégation et doit être évitée.
- Agrégation commune : Les modules partagent les mêmes données globales. Les modifications de la structure des données affectent tous les modules.
- Agrégation externe : Les modules partagent une interface externe, telle qu’un format de fichier ou un protocole de communication.
- Agrégation de contrôle : Un module transmet des informations de contrôle à un autre pour en dicter la logique.
- Agrégation de tampon : Les modules partagent une structure de données complexe (un enregistrement ou un objet), mais n’utilisent que partie de celle-ci.
- Agrégation de données : Les modules partagent uniquement les données nécessaires à leur fonctionnement. C’est l’état souhaité.
Le rôle des diagrammes de paquets 📐
Un diagramme de paquets est un diagramme UML (langage de modélisation unifié) qui montre l’organisation des paquets au sein d’un système. Les paquets agissent comme des espaces de noms pour regrouper des éléments liés. Dans le contexte de l’architecture, ils représentent des modules ou sous-systèmes logiques. Ces diagrammes sont essentiels pour visualiser les dépendances entre les paquets.
Visualisation des dépendances
Les dépendances sont représentées par des flèches pointant du paquet client vers le paquet fournisseur. La direction de la flèche indique que le client dépend du fournisseur. Si cette relation est bidirectionnelle, elle crée une dépendance circulaire, qui constitue un défaut structurel important.
Objectifs clés des diagrammes de paquets :
- Identifier les cycles dans le graphe de dépendances.
- Assurer que les politiques de haut niveau ne dépendent pas des détails de bas niveau.
- Imposer la séparation des préoccupations.
- Fournir un plan directeur pour la refonte.
Péchés courants de couplage à éviter ⚠️
Même les développeurs expérimentés tombent dans des pièges qui introduisent un couplage étroit. Reconnaître ces modèles est la première étape vers une architecture plus saine. Ci-dessous figurent les pièges les plus fréquents rencontrés dans les structures de paquets.
1. Instantiation directe de classes concrètes
Lorsqu’une classe crée une instance d’une autre classe concrète directement en utilisant le nouveauopérateur, elle devient étroitement liée à cette implémentation spécifique. Si la classe concrète change ou doit être remplacée, la classe qui la crée doit être modifiée.
- La piège :
Service service = new ServiceConcrete(); - La solution : Dépendre d’une interface ou d’une classe abstraite.
Service service = new ServiceBaséeSurInterface();
2. Dépendances circulaires
Une dépendance circulaire existe lorsque le paquet A dépend du paquet B, et que le paquet B dépend du paquet A. Cela crée un cycle où aucun des deux paquets ne peut être compilé ou chargé indépendamment. Cela entraîne des séquences d’initialisation complexes et rend le test difficile.
- Impact : Échecs de compilation, fuites de mémoire et récursion infinie au démarrage.
- Résolution : Extraire la fonctionnalité partagée dans un troisième paquet sur lequel dépendent les deux paquets d’origine, mais qui ne dépend de rien.
3. Exposer des détails internes
Exposer des structures de données internes ou des méthodes d’aide dans l’API publique oblige les consommateurs à dépendre des détails d’implémentation. Si vous changez le nom d’un champ interne, tout code qui y accède cesse de fonctionner.
- Principe : Le paquet ne doit exporter que ce qui est nécessaire pour que les clients fonctionnent.
- Règle : Les membres privés et protégés doivent rester cachés à l’intérieur de la frontière du paquet.
4. Ignorer le principe d’inversion de dépendance
Ce principe stipule que les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre d’abstractions. Lorsque la logique de haut niveau est liée à l’accès à une base de données de bas niveau ou à une entrée/sortie de fichiers, le système devient rigide.
5. Sur-fragmentation
Bien que le couplage faible soit bénéfique, diviser les paquets trop finement peut entraîner un surcroît de charge. Si chaque petite fonction nécessite son propre paquet, le système devient difficile à naviguer. L’objectif est de trouver un équilibre entre cohésion et couplage.
Stratégies pour atteindre un couplage faible 🛠️
Construire un système résilient exige des choix de conception réfléchis. Les stratégies suivantes aident à maintenir des paquets faiblement couplés sans sacrifier la fonctionnalité.
1. Utiliser les interfaces et les abstractions
Les interfaces définissent un contrat sans préciser l’implémentation. En programmant selon une interface, vous permettez à l’implémentation de changer sans affecter le code client. C’est la pierre angulaire d’une architecture flexible.
- Définissez des interfaces claires pour tous les services majeurs.
- Assurez-vous que les implémentations sont interchangeables.
- Utilisez des classes abstraites lorsque un comportement partagé est nécessaire, mais privilégiez les interfaces pour les définitions de capacités.
2. Injection de dépendances
Plutôt que d’avoir un module qui crée ses propres dépendances, celles-ci sont fournies depuis l’extérieur. Cela découple le module du processus de création de ses collaborateurs.
- Injection par constructeur :Les dépendances sont passées via le constructeur.
- Injection par mutateur :Les dépendances sont définies via des méthodes publiques.
- Injection par interface :Les dépendances sont fournies à travers une interface spécifique.
3. Patron Facade
Un facade fournit une interface simplifiée à un sous-système complexe. Les clients interagissent avec le facade plutôt qu’avec les classes sous-jacentes. Cela réduit le nombre de dépendances directes que les clients ont vis-à-vis du système.
4. Architecture orientée événements
Les modules peuvent communiquer via des événements plutôt que par des appels directs. Un émetteur envoie un événement sans savoir qui l’écoute. Un abonné réagit à l’événement sans savoir qui l’a envoyé. Cela élimine complètement le couplage direct.
- Découple l’expéditeur et le destinataire.
- Permet un traitement asynchrone.
- Améliore la scalabilité.
Mesurer et maintenir la santé des paquets 📊
Concevoir pour un couplage faible est un processus continu. Les métriques aident à quantifier la qualité de l’architecture au fil du temps. Plusieurs métriques standards existent pour évaluer les dépendances entre paquets.
Métriques clés pour le couplage
| Métrique | Définition | Tendance souhaitée |
|---|---|---|
| Couplage afférent (Ca) | Nombre de packages qui dépendent du package actuel. | Élevé pour les packages principaux stables. |
| Couplage sortant (Ce) | Nombre de packages sur lesquels le package actuel dépend. | Faible pour tous les packages. |
| Instabilité (I) | Ratio de Ce sur (Ca + Ce). | Les valeurs proches de 1 sont instables ; les valeurs proches de 0 sont stables. |
| Absence de dépendances circulaires | Nombre de chemins circulaires dans le graphe de dépendances. | Zéro est l’objectif. |
Techniques de restructuration
Lorsque les métriques indiquent un couplage élevé, des techniques de restructuration spécifiques peuvent restaurer l’équilibre.
- Déplacer une méthode : Déplacer une méthode vers la classe où elle est utilisée plus fréquemment ou où elle appartient logiquement.
- Extraire une interface : Créer une interface pour une classe afin de permettre à d’autres classes de dépendre de l’abstraction.
- Descendre une méthode : Déplacer une méthode depuis une superclasse vers une sous-classe spécifique si elle ne s’applique que là.
- Monter une méthode : Déplacer une méthode depuis une sous-classe vers une superclasse pour réduire la duplication.
L’impact sur la vitesse d’évolution de l’équipe et la qualité 🚀
La qualité structurelle de la base de code influence directement l’aspect humain du développement logiciel. Les équipes travaillant avec des systèmes fortement couplés rencontrent des frictions. Les modifications prennent plus de temps à implémenter, et le risque d’introduire des bogues augmente.
Maintenabilité
Les packages lâches rendent le code plus facile à comprendre. Les développeurs peuvent se concentrer sur un package sans avoir à comprendre les internes de chaque autre package. Cela réduit la charge cognitive et accélère l’intégration des nouveaux membres de l’équipe.
Testabilité
Le test est considérablement plus facile lorsque les dépendances sont injectées. Les objets fictifs peuvent remplacer les implémentations réelles lors des tests unitaires. Cela permet des boucles de retour rapides sans avoir à démarrer des services externes comme des bases de données ou des files de messages.
Évolutivité
À mesure que le système grandit, de nouvelles fonctionnalités peuvent être ajoutées aux packages existants sans briser la fonctionnalité existante. Un couplage lâche garantit que l’architecture peut évoluer pour répondre à de nouvelles exigences sans avoir à tout réécrire.
Développement parallèle
Lorsque les paquets sont indépendants, plusieurs développeurs peuvent travailler simultanément sur différentes parties du système. Cela réduit les conflits de fusion et permet une livraison parallèle des fonctionnalités.
Scénarios du monde réel et application 🌍
Pour bien comprendre ces concepts, envisagez leur application aux couches architecturales typiques. Dans une architecture en couches standard, la couche présentation dépend de la couche métier, qui elle-même dépend de la couche données. La couche données ne doit pas connaître la logique métier.
Si la logique métier appelle directement des méthodes de base de données, cela viole la règle de dépendance. La couche métier doit appeler une interface de répertoire. L’implémentation du répertoire gère l’interaction avec la base de données. Cette séparation permet de changer la technologie de base de données (par exemple, du SQL au NoSQL) sans modifier la logique métier.
Gestion des systèmes hérités
Le refactoring du code hérité est difficile. Il est souvent préférable d’introduire un nouveau paquet qui agit comme un wrapper autour du code hérité. Cela crée une frontière. Au fil du temps, le code hérité peut être remplacé tout en maintenant le contrat via le nouveau paquet.
- Ne refactorez pas tout d’un coup.
- Créez des interfaces pour les composants hérités.
- Migrez progressivement les fonctionnalités vers de nouveaux paquets.
- Utilisez des adaptateurs pour combler les écarts entre les anciens et les nouveaux systèmes.
Meilleures pratiques pour l’organisation des paquets 📂
Organiser les paquets exige de la discipline. Il n’existe pas une seule manière correcte, mais plusieurs principes aident à maintenir l’ordre.
- Regrouper par fonction :Regroupez les fonctionnalités liées. Un paquet nommé
Paiementdoit contenir toute la logique liée aux paiements. - Regrouper par domaine : Si vous utilisez la conception pilotée par le domaine, organisez les paquets par domaine métier plutôt que par couche technique.
- Respectez les frontières :Ne permettez pas aux paquets de s’importer mutuellement de manière inutile. Utilisez
interneles modificateurs de visibilité où disponibles. - Limitez la profondeur :Évitez les hiérarchies d’héritage profondes qui rendent la navigation difficile.
- Nomination cohérente :Utilisez des noms clairs et descriptifs pour les paquets. Évitez les abréviations non standard.
Réflexions finales sur l’intégrité architecturale 🧠
Concevoir pour un couplage faible est un effort continu. Il exige une vigilance lors des revues de code et une volonté de refactorer lorsque la dette technique s’accumule. L’objectif n’est pas la perfection, mais la progression. En comprenant les types de couplage, en utilisant des diagrammes de paquets et en appliquant des stratégies comme l’inversion de dépendance, les équipes peuvent construire des systèmes capables de résister aux changements.
Souvenez-vous qu’une architecture n’est pas un événement ponctuel. Elle évolue avec le produit. Revoyez régulièrement les dépendances des paquets pour vous assurer qu’elles restent valides. Utilisez des outils automatisés pour détecter les violations des règles de dépendance. Cette approche proactive empêche les petits problèmes de devenir des échecs structurels.
En fin de compte, la valeur du couplage faible réside dans la liberté qu’il offre. Il permet aux équipes d’innover sans craindre de briser la fondation. Il transforme le logiciel d’un bloc rigide en un cadre souple capable de s’adapter aux besoins futurs. 🏗️