専用DFDサポートで、より明確なシステム分析を実現
Visual Paradigmは、GaneとSarsonのデータフローダイアグラム(DFD)表記法に対する専用サポートを導入することで、構造化分析への取り組みをさらに進展させました。システムアナリストおよびソフトウェアエンジニアにとって、このアップデートは正確で階層的なシステムモデルを作成する上で大きな飛躍を意味します。Gane-Sarson記号と規則に特化した環境を統合することで、チームは複雑な情報システムの要件を、これまでにない明確さと効率で分析、文書化、共有できるようになりました。要件これまでにない明確さと効率で。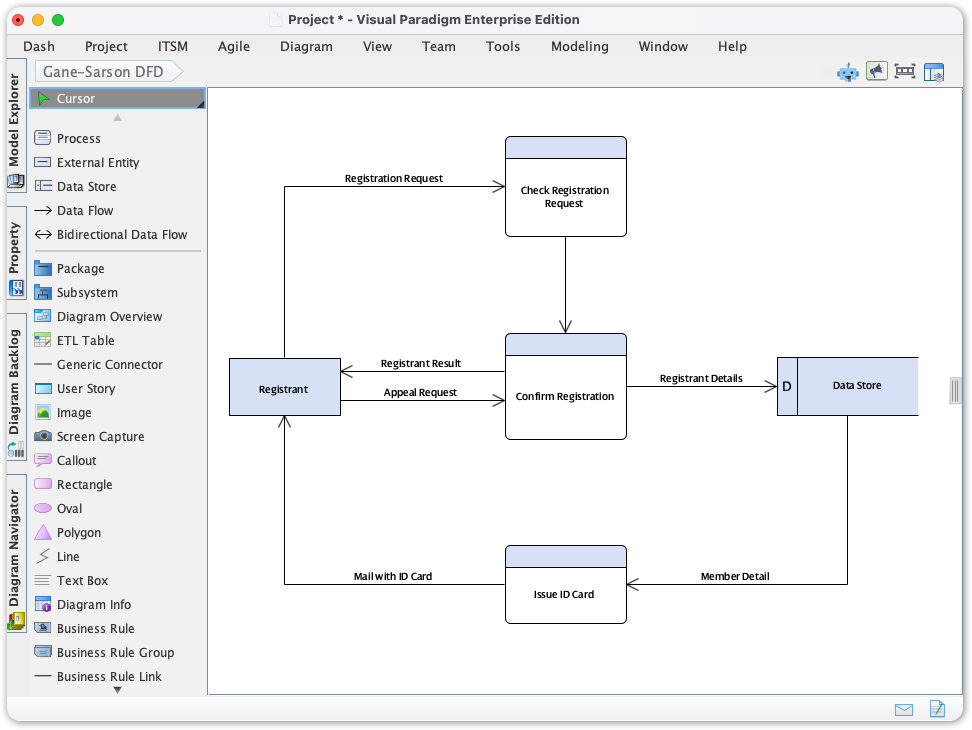
この包括的なガイドでは、GaneとSarson表記法の基本的な概念、Visual Paradigmの新機能を活用して一般的なモデリング課題を克服する方法、そして高品質な文書作成のためのベストプラクティスについて解説します。
主要な概念:GaneとSarsonのDFDを理解する
ツールに取り組む前に、GaneとSarson表記法の基礎となる要素を理解することが不可欠です。この表記法は、Yourdon/DeMarcoなどの他の表記法と視覚的に明確に異なります。
- プロセス:データの変換を表します。GaneとSarsonでは、通常、識別番号、説明(動詞句)、およびタスクを実行する物理的場所または人物を含む丸みを帯びた長方形(またはソフトボックス)として描かれます。
- データストア:停止中のデータを表します。特徴的に、GaneとSarsonでは、右側が開いた長方形を使用して、データベース、ファイル、またはリポジトリを表します。
- 外部エンティティ:システム境界外のデータの発信元または受信先を表します。通常、影を付けた正方形または長方形として描かれ、3次元的な印象を与えます。
- データフロー:他のコンポーネントをつなぐ矢印で、プロセス、ストア、エンティティ間での情報パケットの移動を示します。
レガシーツールにおける一貫性の課題
このリリース以前、システムアナリストは汎用的な図作成ツールを使って堅牢なGane-Sarson DFDを作成しようとする際、大きな障害に直面することがありました。主な課題は以下の通りです:
- 表記のずれ:専用の記号セットがなければ、大規模なプロジェクトにわたり特定の視覚的基準(たとえば、開いたデータストア記号)を維持することが難しく、一貫性のない文書化を招くことになりました。
- 重複作業:ユーザーは、一貫性を確保するために、要素の手動での整列やボックスのサイズ調整に貴重な時間を費やしており、特に図をより低い詳細レベルに分解する際には顕著でした。
- 再利用性の低さ:異なるレベル間でデータストアやプロセスを手動で再利用することは、モデリングエラーと論理の断絶のリスクを高めます。
ガイドライン:アクセス方法とモデリングの開始方法
Visual Paradigmは、カスタムシェイプの設定なしにアナリストがすぐにシステム分析に取り組めるように、ワークフローを簡素化しました。以下の手順に従って開始してください:
- 図のメニューにアクセスする:アプリケーションツールバーに移動するVisual Paradigm Desktop そして、図 メニューを開く。
- 作成を開始する: 選択する新規 図作成インターフェースを開く。
- 標準を選択する: 検索または選択パネルで、Gane-Sarson DFD.
- 確認: クリックする次へ 進む。
- モデリングを開始する: 今後、図パレットに専用のGane-Sarson要素が表示されます。これらの要素をドラッグアンドドロップして、プロセスとデータフローを定義してください。
構造化分析のベストプラクティス
新しいGane-Sarsonツールの効果を最大化するため、業界標準のベストプラクティスに従ってください:
- 厳格なレベル分け: システムを外部エンティティと相互作用する単一のプロセスとして示すコンテキスト図(レベル0)から始めます。これをレベル1図に分解して主要なサブプロセスを示します。
- バランスの維持: レベル間で入力と出力が保存されることを確認してください。レベル1でプロセスに入力されるデータは、レベル2でのそのプロセスの分解においても考慮される必要があります。
- 意味のある命名: プロセスには強力な動詞+名詞の表現を使用する(例:「税金を計算する」など、「計算」などではなく)し、データストアには名詞表現を使用する(例:「顧客データベース」など)。
- 要素の再利用: Visual Paradigmのリポジトリ機能を利用して、データストアと外部エンティティを再利用する。これにより、データストア名が変更された場合でも、すべての図面にわたる更新.
よくある間違いとその回避方法
高度なツールを用いても論理的な誤りが発生する可能性があります。以下の落とし穴に注意してください:
- ブラックホール: 入力データフローはあるが、出力がないプロセス。 解決策: すべてのプロセスが入力に基づいてデータを生成することを確認する。
- ミラクル: 入力なしで出力を生成するプロセス。 解決策: ロジックを確認してください。データは空から生成できません。
- グレーアホル: 出力データが入力データから論理的に導けないプロセス(例:入力「生年月日」、出力「住所」)。 解決策: 入力が目的の出力を生成するのに十分であることを確認する。
- 視覚的なごちゃごちゃ: データフロー線が過度に交差している。 解決策: 自動整列ツールを使用してレイアウトを再編成する、または外部エンティティ(アスタリスクでマークされたもの)を複製して接続を簡素化する。
効率化のためのヒントとテクニック
Visual Paradigmの更新には、単なる描画を越えた機能が含まれています:
- 自動化を活用: 智能的な整列ツールとスナップガイドを使用する。手動でピクセルをずらす時間を無駄にしないでください。ツールに要素をプロフェッショナルなレイアウトで自動的に整列させましょう。
- 要件に集中: シンボルの準拠はソフトウェアが処理するため、『描画』から『ドキュメント作成』へと意識を転換してください。システム境界内のデータフローの論理を磨く時間を費やしましょう。さらに、仕様書からエンティティを直接特定できるような「テキスト解析」ツールを活用してこのプロセスを強化することもできます。
- 権威あるモデル作成: 構造化分析の基準に準拠することを保証するために、特定のGane-Sarsonパレットを使用する。これは、標準表記に厳格なステークホルダーに提示する際に特に有用です。
例:前と後
システムアナリストが「注文処理システム.”
前:汎用図面作成ツール
アナリストは手動で長方形を描き、データストアを作成するために一辺を消去しようとします。この形状を20回コピー&ペーストします。その後、テキスト「在庫データベース」を表示するには形状が小さすぎるのに気づきます。1つだけサイズを変更しましたが、残りの19個は小さいままであり、プロフェッショナルでない、一貫性のない見た目になります。接続線は静的な線であり、オブジェクトを移動しても追跡しません。
後:Visual Paradigm Gane-Sarsonサポート
アナリストはGane-Sarsonパレットから「データストア」ツールを選択します。キャンバス上に配置すると、自動的に正しい開放型のスタイルでレンダリングされます。テキスト「在庫データベース」を入力すると、形状がテキストに合わせて調整されます。グローバルリポジトリを使用して、この特定のデータストアをレベル2の図で再利用します。名前を「在庫リポジトリ」に変更すると、即座にすべての場所で更新されます。スナップガイドにより、「在庫確認」プロセスと正確に整合します。