











La construction de systèmes logiciels robustes et évolutifs exige plus que la simple rédaction de code fonctionnel. Elle exige une approche structurée qui équilibre la flexibilité et la cohérence. Dans le domaine de l’analyse et de la conception orientées objet, peu de modèles offrent la stabilité architecturale nécessaire à la création de frameworks comme le modèle de méthode de modèle. Ce modèle de conception comportemental fournit un squelette pour les algorithmes, permettant aux sous-classes de redéfinir des étapes spécifiques sans modifier la structure globale. En exploitant ce modèle, les développeurs peuvent créer des frameworks extensibles qui imposent un flux de travail spécifique tout en encourageant la personnalisation là où cela compte le plus. Ce guide explore les mécanismes, les avantages et les applications pratiques de ce modèle dans la conception architecturale.
Comprendre le modèle 🧩
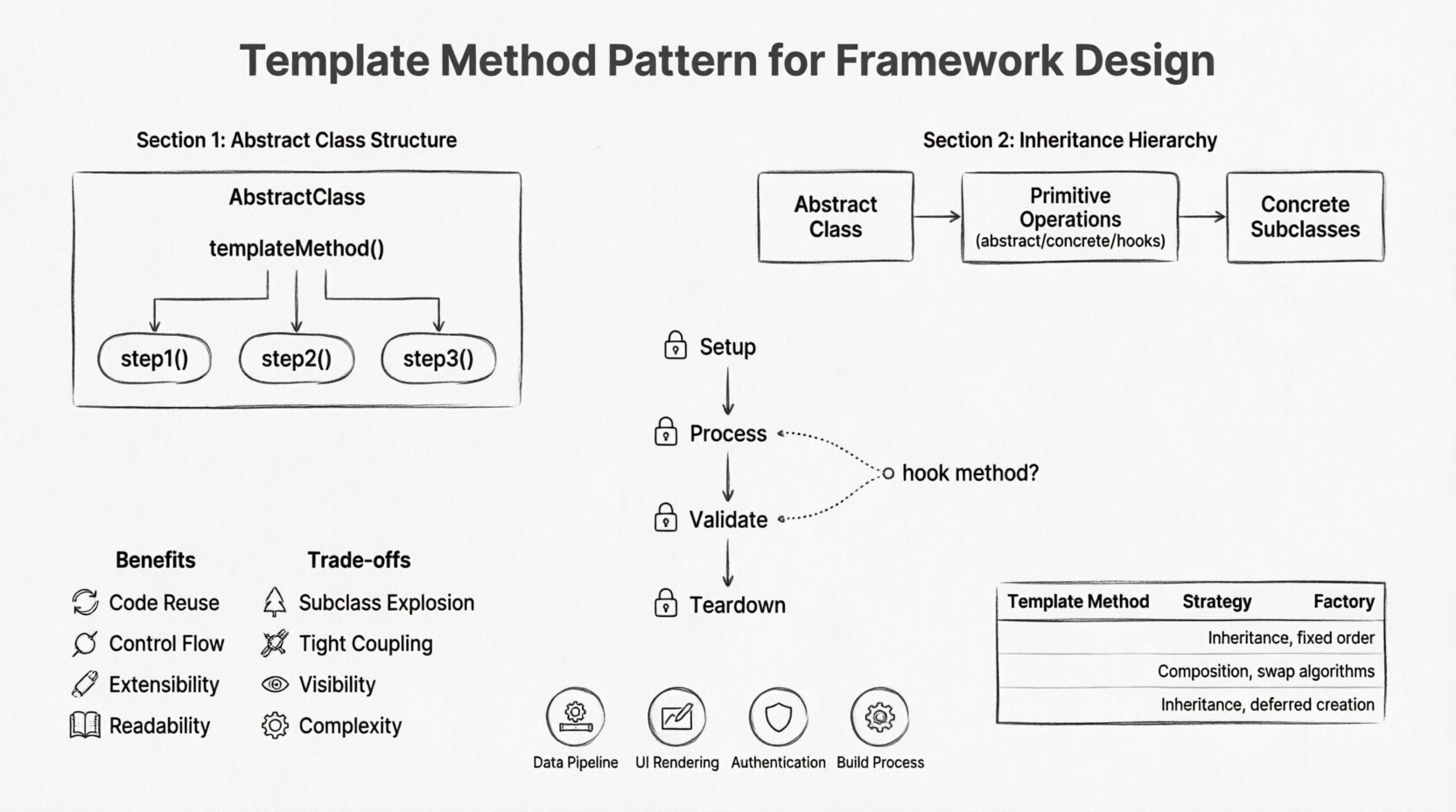
Le modèle de méthode de modèle définit le squelette d’un algorithme dans une opération, reportant certaines étapes aux sous-classes. Il permet aux sous-classes de redéfinir certaines étapes d’un algorithme sans modifier la structure de l’algorithme. Cette séparation est cruciale lors de la conception de frameworks, car elle établit un contrat entre le framework et l’utilisateur du framework.
Imaginez un processus impliquant plusieurs phases distinctes : initialisation, traitement, validation et nettoyage. L’ordre de ces phases doit rester constant pour garantir l’intégrité du système. Toutefois, la logique spécifique dans la phase « traitement » peut varier selon le type de données ou les exigences métiers. Le modèle de méthode de modèle résout cela en maintenant le flux de contrôle dans une classe de base tout en permettant aux classes dérivées d’injecter des comportements spécifiques.
-
Flux de contrôle : Les étapes invariantes sont définies dans la classe abstraite.
-
Logique personnalisée : Les étapes variables sont laissées sous forme de méthodes abstraites ou de points d’ancrage.
-
Consistance : Le processus global reste stable dans toutes les implémentations.
Cette approche réduit considérablement la duplication de code. Sans ce modèle, chaque sous-classe devrait implémenter l’algorithme entier, ce qui entraîne du code répétitif et des incohérences potentielles. En centralisant la logique commune, la maintenance devient plus simple et le risque d’erreurs diminue.
Composants fondamentaux 🔒
Pour implémenter efficacement ce modèle, il faut comprendre les rôles spécifiques joués par les différents éléments au sein de la hiérarchie de classes. La structure repose fortement sur l’abstraction et l’héritage.
1. La classe abstraite
Cette classe contient le méthode de modèle. Elle définit la séquence des opérations qui constituent l’algorithme. Elle appelle des opérations primitives, qui peuvent être abstraites ou concrètes, à des points spécifiques de la séquence. La méthode de modèle elle-même est généralement finale afin d’empêcher les sous-classes de modifier le flux de l’algorithme.
2. Opérations primitives
Ce sont les étapes individuelles au sein de l’algorithme. Elles peuvent être :
-
Abstraites : Aucune implémentation fournie ; les sous-classes doivent les redéfinir.
-
Concrètes : Une implémentation par défaut est fournie dans la classe de base.
-
Méthodes crochet : Méthodes facultatives que les sous-classes peuvent redéfinir pour ajouter de la logique.
3. Sous-classes concrètes
Ces classes héritent de la classe abstraite et fournissent les implémentations spécifiques pour les opérations primitives. Elles n’interfèrent pas avec la méthode de modèle. Leur responsabilité est uniquement de définir le comportement des étapes spécifiques.
Application à l’architecture des frameworks 🏛️
Les frameworks exigent souvent une inversion de contrôle où le framework appelle le code de l’utilisateur, plutôt que l’inverse. Le modèle de méthode de modèle est le fondement de cette inversion. Il permet au framework de définir le cycle de vie d’un objet tout en offrant au développeur des points d’ancrage pour injecter de la logique métier.
Considérez un pipeline de traitement de données. Le cadre de travail gère l’ouverture des ressources, l’exécution des étapes du pipeline et la fermeture des ressources. Le développeur n’a besoin que de définir la logique de transformation des données. Cette séparation garantit que la gestion des ressources est effectuée de manière cohérente, quelle que soit la manière dont les données sont traitées.
|
Composant |
Responsabilité |
Exemple |
|---|---|---|
|
Méthode modèle |
Définit l’ossature de l’algorithme |
|
|
Opération primitive |
Définit des étapes spécifiques |
|
|
Méthode crochet |
Permet une personnalisation facultative |
|
Cette structure soutient le Principe d’inversion de dépendance. Les modules de haut niveau (le cadre de travail) ne dépendent pas des modules de bas niveau (la logique utilisateur) ; les deux dépendent d’abstractions. Ce découplage rend le système plus modulaire et plus facile à tester.
Le rôle des méthodes crochet 🪝
Les méthodes crochet sont un type spécifique d’opération primitive qui fournit une implémentation vide dans la classe de base. Elles permettent aux sous-classes de les remplacer si elles doivent effectuer des actions, mais elles n’ont pas à le faire si le comportement par défaut est suffisant. Cela ajoute de la flexibilité sans obliger la sous-classe à implémenter une logique qu’elle n’a pas besoin.
-
Exécution facultative : Si une sous-classe remplace le crochet, le cadre de travail l’exécute. Sinon, il l’ignore ou ne fait rien.
-
Extensibilité : Les développeurs peuvent ajouter des effets secondaires, des journaux ou une validation sans modifier l’algorithme principal.
-
Notification : Les cadres de travail utilisent souvent des crochets pour informer les développeurs lorsqu’un événement spécifique se produit, par exemple avant ou après une transaction.
Utiliser des crochets évite la nécessité de plusieurs sous-classes qui ne diffèrent que par un petit détail. Au lieu de cela, une seule hiérarchie de sous-classes peut gérer divers scénarios grâce à des remplacements facultatifs. Cela maintient la hiérarchie de classes plus plate et plus facile à gérer.
Avantages et inconvénients ⚖️
Comme tout patron de conception, le patron Méthode modèle présente des forces et des faiblesses. Comprendre celles-ci est essentiel pour prendre des décisions architecturales éclairées.
Avantages
-
Réutilisation du code : La logique commune est écrite une seule fois dans la classe de base, réduisant ainsi la duplication.
-
Flux de contrôle : Le cadre maintient le contrôle sur l’ordre des opérations, assurant ainsi une cohérence.
-
Extensibilité : De nouvelles variantes peuvent être ajoutées en créant de nouvelles sous-classes sans modifier le code existant.
-
Lisibilité : La structure de l’algorithme est visible dans la méthode de modèle, offrant une route claire.
Compromis
-
Explosion des sous-classes : La création de nombreuses sous-classes peut entraîner une hiérarchie profonde et étendue, difficile à naviguer.
-
Couplage étroit : Les sous-classes sont couplées à l’implémentation de la classe de base. Les modifications dans la méthode de modèle affectent toutes les sous-classes.
-
Visibilité : Dans certaines langues, la méthode de modèle doit être publique ou protégée, exposant ainsi des détails d’implémentation.
-
Complexité : Pour des tâches simples, le modèle pourrait introduire une complexité inutile par rapport à une fonction directe.
Lors de la décision d’utiliser ce modèle, évaluez la complexité de l’algorithme. Si le processus est stable mais que les étapes varient, il constitue un candidat fort. Si la logique change fréquemment ou si les étapes sont sans rapport, d’autres modèles pourraient être plus adaptés.
Stratégie d’implémentation 🛠️
Mettre en œuvre ce modèle nécessite une approche disciplinée pour s’assurer qu’il apporte de la valeur plutôt que de la complexité. Suivez ces étapes pour l’intégrer à votre conception.
-
Identifiez l’invariant : Déterminez quels étapes de l’algorithme sont identiques dans toutes les situations. Elles forment le cœur de la méthode de modèle.
-
Identifiez la variante : Identifiez les étapes qui varient selon le cas d’utilisation spécifique. Ce doivent être des opérations primitives.
-
Créez la classe abstraite : Définissez la méthode de modèle et les opérations primitives abstraites.
-
Implémentez les classes concrètes : Créez des sous-classes qui implémentent les opérations primitives. Assurez-vous qu’elles ne remplacent pas la méthode de modèle.
-
Ajoutez des points d’ancrage : Là où un comportement facultatif est nécessaire, ajoutez des méthodes de point d’ancrage vides à la classe de base.
-
Test d’extensibilité :Vérifiez que de nouvelles sous-classes peuvent être ajoutées sans modifier la classe de base.
Pendant l’implémentation, maintenez une distinction claire entre le quoi (l’algorithme) et le comment (les étapes spécifiques). Cette séparation garantit que le cadre reste robuste même au fur et à mesure que les exigences évoluent.
Péchés courants ⚠️
Même les développeurs expérimentés peuvent tomber dans des pièges lors de l’application de ce modèle. Être conscient de ces problèmes courants aide à les éviter.
-
Surutilisation de l’abstraction :N’abstrayez pas chaque méthode. Abstrayez uniquement là où il existe un besoin clair de variation. Trop d’abstraction conduit à la confusion.
-
Dépendances cachées :Les sous-classes pourraient dépendre de l’état de la classe de base. Assurez-vous que la gestion d’état est claire et sécurisée en thread si nécessaire.
-
Violer le contrat :Les sous-classes ne doivent pas appeler directement la méthode de modèle. Faire cela peut contourner le flux prévu.
-
Ignorer la gestion des erreurs :Assurez-vous que la gestion des erreurs est cohérente dans toute la hiérarchie. Une erreur à une étape ne doit pas laisser le système dans un état incohérent.
Les revues régulières de code peuvent aider à identifier ces pièges tôt. Concentrez-vous sur le couplage entre la classe de base et les sous-classes. Si des modifications dans l’une nécessitent des modifications dans l’autre, le design pourrait être trop étroitement couplé.
Comparaison avec d’autres modèles 🔄
Bien que le modèle Méthode de modèle soit puissant, ce n’est pas toujours le meilleur choix. Comparer ce modèle avec des modèles similaires clarifie quand l’utiliser.
|
Modèle |
Objectif |
Relation |
Meilleur usage lorsque |
|---|---|---|---|
|
Méthode de modèle |
Structure de l’algorithme |
Héritage |
Les étapes varient, l’ordre est fixe |
|
Modèle Stratégie |
Sélection de l’algorithme |
Composition |
Les algorithmes sont interchangeables |
|
Méthode usine |
Création d’objets |
Héritage |
Instantiation différée |
Le patron Stratégie est souvent confondu avec le patron Méthode Template. La différence clé réside dans la manière dont la variation est obtenue. La Méthode Template utilise l’héritage pour modifier des étapes au sein d’un seul algorithme. La Stratégie utilise la composition pour échanger des algorithmes entiers. Si vous devez modifier tout le processus, utilisez la Stratégie. Si vous devez modifier des étapes spécifiques au sein d’un processus, utilisez la Méthode Template.
Meilleures pratiques pour la maintenabilité 📋
Pour garantir que le patron reste utile au fil du temps, suivez ces directives.
-
Nommage clair : Nommez la méthode template pour refléter le processus global (par exemple,
processOrder). Nommez les opérations primitives pour refléter l’étape spécifique (par exemple,validateOrder). -
Abstraction minimale : Gardez la classe de base centrée. Si elle devient trop grande, envisagez de diviser les responsabilités en plusieurs classes de base.
-
Documentation : Documentez la séquence attendue des appels. Les sous-classes doivent connaître l’ordre dans lequel elles sont appelées.
-
Gestion des versions : Soyez prudent lors de la modification de la méthode template. Changer l’ordre des appels peut casser les sous-classes existantes. Utilisez des avertissements de dépréciation si des modifications sont nécessaires.
-
Séparation des interfaces : Assurez-vous que les sous-classes n’implémentent pas les méthodes qu’elles n’utilisent pas. Utilisez des classes abstraites ou des interfaces pour définir clairement le contrat.
La maintenabilité concerne la longévité. Un cadre bien conçu doit résister aux changements de besoins sans nécessiter une refonte complète. Le patron Méthode Template soutient cela en isolant les modifications aux méthodes spécifiques.
Scénarios et cas d’utilisation 🎯
Ce patron brille dans des contextes architecturaux spécifiques où la cohérence et l’extensibilité sont primordiales.
Pipelines de traitement de données
Lors du traitement des données à travers plusieurs étapes (ingestion, transformation, stockage), le cadre gère le flux. L’utilisateur définit la logique de transformation. Cela garantit que la journalisation, la gestion des erreurs et le nettoyage des ressources se produisent de manière cohérente.
Flux de rendu d’interface utilisateur
Les interfaces utilisateur suivent souvent un cycle de vie standard : initialisation, rendu, gestion des événements, suppression. Le cadre gère ce cycle de vie, tandis que le composant définit la logique de rendu spécifique. Cela garantit une expérience utilisateur cohérente à travers différents widgets.
Séquences d’authentification
L’authentification implique souvent la vérification des identifiants, la validation des jetons et la journalisation des sessions. Le cadre gère la séquence, tandis que l’utilisateur définit la manière dont les identifiants sont vérifiés (par exemple, base de données, LDAP, API).
Processus de construction
Les constructions logicielles impliquent la compilation, les tests et le conditionnement. Le système de construction gère l’ordre. L’utilisateur définit les drapeaux de compilation spécifiques ou les scripts de test.
Dans tous ces cas, le fil conducteur commun est une séquence fixe d’opérations avec un contenu variable. Le patron Méthode Template fournit la structure nécessaire pour gérer cette complexité.
Réflexions finales sur l’architecture 🏁
Le patron Méthode Template est un outil fondamental pour quiconque conçoit des cadres orientés objet. Il offre un équilibre entre contrôle et flexibilité, essentiel pour les systèmes à grande échelle. En définissant l’esquelette de l’algorithme dans une classe de base et en permettant aux sous-classes de remplir les détails, les développeurs peuvent créer des systèmes à la fois stables et adaptables.
Le succès avec ce patron dépend d’une conception soigneuse. Identifiez clairement les étapes invariantes. Définissez précisément les étapes variables. Utilisez les points d’ancrage avec parcimonie pour éviter une complexité inutile. Lorsqu’il est appliqué correctement, il conduit à un code plus propre, à une maintenance plus facile et à des cadres plus robustes.
Souvenez-vous que les patrons de conception sont des outils, pas des règles. Utilisez-les là où ils correspondent au problème. Si l’algorithme change trop souvent, envisagez une approche différente. Si les étapes sont trop simples, une fonction pourrait suffire. Mais pour les flux de travail complexes et structurés, ce patron reste un choix fiable en ingénierie logicielle professionnelle.