











Dans le domaine de l’analyse et de la conception orientées objet, l’architecture d’un système logiciel détermine sa durée de vie et sa capacité d’adaptation. L’un des indicateurs les plus critiques pour évaluer la qualité du design est le degré de couplage entre les composants. Réduire le couplage n’est pas simplement un exercice théorique ; c’est une nécessité pratique pour maintenir des systèmes qui doivent évoluer au fil du temps. Lorsque les dépendances sont minimisées, le système devient plus souple, permettant d’isoler les modifications et de les déployer avec confiance.
Ce guide explore les mécanismes du couplage, les types de dépendances qui entravent la flexibilité, et les stratégies spécifiques utilisées pour atteindre une architecture à faible couplage. En comprenant ces principes, les développeurs peuvent concevoir des systèmes plus faciles à tester, à maintenir et à étendre sans effets secondaires involontaires.
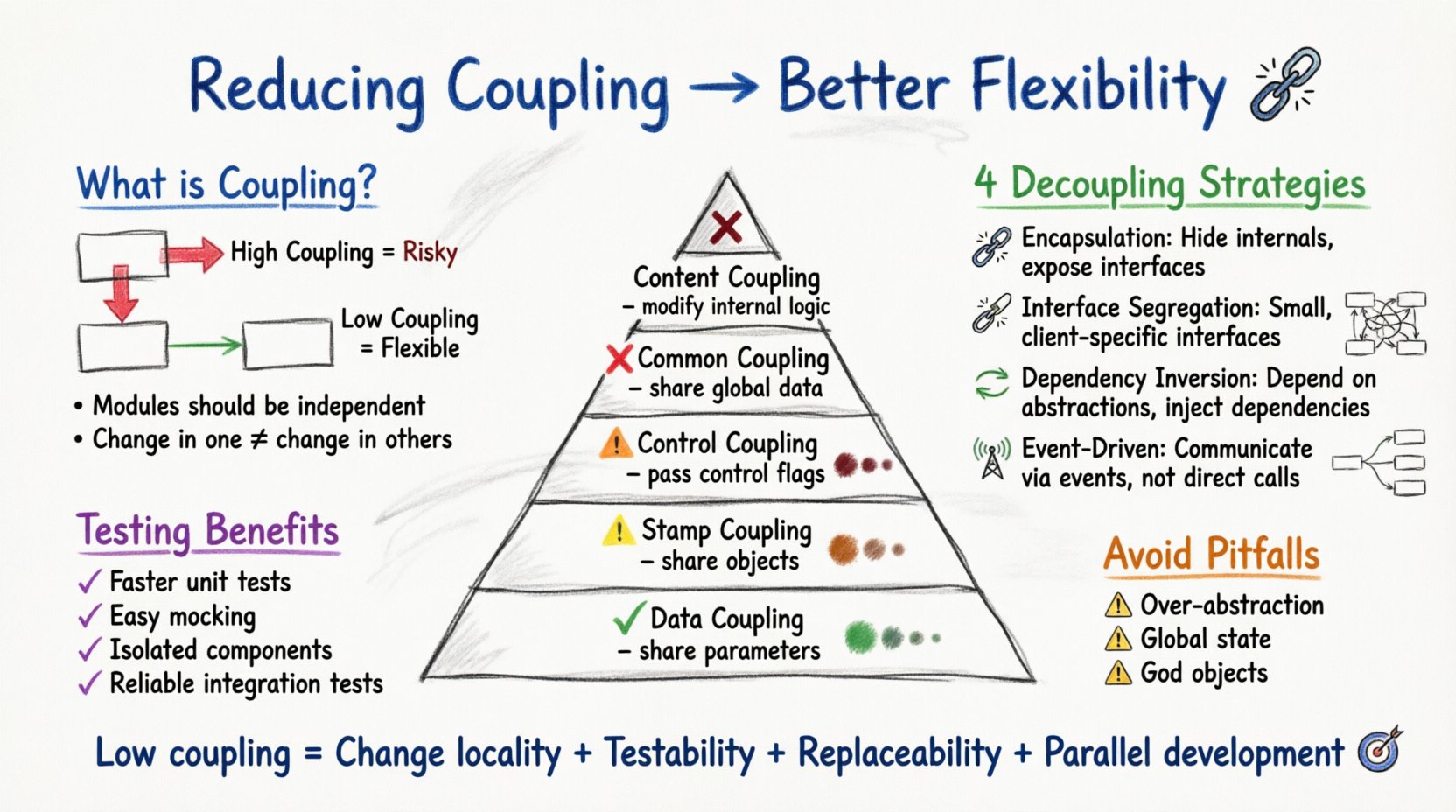
Comprendre le concept de couplage 🔗
Le couplage fait référence au degré d’interdépendance entre les modules logiciels. Il mesure à quel point deux routines ou modules sont étroitement liés. Dans un système bien conçu, les modules doivent être suffisamment indépendants pour qu’un changement dans l’un n’entraîne pas nécessairement un changement dans l’autre. Un fort couplage crée un réseau de dépendances où une modification dans une seule classe peut se propager à l’ensemble de l’application, entraînant une instabilité.
Inversement, un faible couplage implique que les modules sont faiblement connectés. Cette séparation permet aux équipes de travailler simultanément sur différentes parties du système sans coordination constante. L’objectif est de réduire le couplage tout en maintenant une forte cohésion, où les éléments au sein d’un même module sont fortement liés entre eux.
- Fort couplage :Les modules dépendent fortement des détails internes d’autres modules. Les modifications sont difficiles et risquées.
- Faible couplage :Les modules interagissent à travers des interfaces stables. Les modifications sont localisées et contenues.
Types de couplage 📊
Pour réduire efficacement le couplage, il faut d’abord comprendre les différentes formes qu’il peut prendre. Des niveaux variés de couplage existent, allant de bénins à très néfastes. Le tableau ci-dessous décrit les types courants de couplage présents dans les systèmes orientés objet.
| Type de couplage | Description | Impact sur la flexibilité |
|---|---|---|
| Couplage par données | Les modules partagent des données par le biais de paramètres. | Faible impact (souhaitable) |
| Couplage par tampon | Les modules partagent une structure de données composite (objet). | Impact modéré |
| Couplage par contrôle | Un module transmet des drapeaux de contrôle à un autre. | Fort impact |
| Couplage commun | Les modules partagent des données globales. | Très fort impact |
| Couplage par contenu | Un module modifie la logique interne d’un autre. | Impact critique |
Bien que certains niveaux de couplage soient inévitables, l’objectif est de minimiser la gravité de ces dépendances. Le couplage de données est souvent acceptable car il représente un simple passage d’informations. Toutefois, le couplage de contrôle et le couplage de contenu introduisent des flux logiques cachés qui rendent le système fragile.
L’impact sur la maintenance et les tests 🛠️
Lorsque le couplage est élevé, le coût de maintenance augmente de manière exponentielle. Les développeurs passent plus de temps à comprendre comment un changement dans une zone affecte une autre qu’à écrire du nouveau code. Ce phénomène est souvent appelé l’« effet domino ». Une petite correction de bogues dans une classe utilitaire peut briser la logique métier centrale, entraînant des erreurs de régression.
Défis liés aux tests
Le test unitaire devient considérablement plus difficile avec un couplage serré. Si une classe dépend d’une connexion à une base de données, d’un service réseau ou d’un chemin spécifique du système de fichiers, elle ne peut pas être testée de manière isolée. Les tests deviennent lents, instables et nécessitent une configuration complexe.
- Difficulté de simulation :Les dépendances doivent être simulées ou émulées pour exécuter les tests.
- Fragilité des tests :Les modifications dans les classes dépendantes cassent les tests existants.
- Complexité d’intégration :Les tests doivent démarrer des services externes, ralentissant ainsi la boucle de retour.
Coûts de maintenance
La flexibilité est directement corrélée à la capacité de modifier le système. Un couplage serré réduit la possibilité d’échanger des implémentations. Par exemple, si un module de traitement des paiements est fortement couplé à une API spécifique de passerelle de paiement, passer à un autre fournisseur exige de réécrire la logique centrale. Un couplage lâche permet à l’implémentation de changer tout en maintenant l’interface stable.
Stratégies de dé-couplage 🧩
Réduire le couplage nécessite des décisions de conception intentionnelles. Ce n’est pas un processus qui se produit automatiquement ; il doit être intégré de manière intentionnelle dans le système dès le départ. Les stratégies suivantes fournissent un cadre pour atteindre une indépendance entre les composants.
1. Encapsulation et abstraction
L’encapsulation masque l’état interne d’un objet. En n’exposant que les méthodes nécessaires, vous empêchez les autres modules d’accéder ou de modifier directement les données internes. Cela réduit la surface d’erreurs potentielles.
- Définissez des interfaces claires sur ce qu’une classe fait, et non sur la manière dont elle le fait.
- Gardez les données privées et n’exposez des accesseurs publics (getters ou setters) que lorsque cela est absolument nécessaire.
- Évitez de révéler les détails d’implémentation tels que des tableaux internes ou des schémas de base de données.
2. Ségrégation des interfaces
Les interfaces doivent être spécifiques au client. Une grande interface monolithique oblige les clients à dépendre de méthodes qu’ils n’utilisent pas. Cela crée un couplage inutile. En divisant les interfaces en petites interfaces ciblées, les modules ne dépendent que de la fonctionnalité qu’ils utilisent réellement.
- Divisez les grandes interfaces en groupes plus petits et cohérents.
- Assurez-vous qu’aucun module ne dépend d’une interface contenant des méthodes non pertinentes.
- Cela permet aux implémentations de varier sans affecter les clients non liés.
3. Inversion des dépendances
Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre d’abstractions. Ce principe permet au système de remplacer les détails de bas niveau sans modifier la logique de haut niveau.
- Utilisez des interfaces ou des classes abstraites pour définir les dépendances.
- Injectez les dépendances plutôt que de les créer directement à l’intérieur de la classe.
- Cela permet d’utiliser différentes implémentations (par exemple, un mock pour les tests, un service réel pour la production) sans modifier le code du consommateur.
4. Architecture orientée événements
Au lieu des appels de méthode directs, les modules peuvent communiquer par le biais d’événements. Lorsqu’un module émet un événement, les autres modules qui écoutent peuvent y réagir. Cela élimine la nécessité pour l’émetteur de savoir qui écoute.
- Découpler l’expéditeur du destinataire.
- Permettre à plusieurs écouteurs de répondre à un seul événement.
- Réduire la nécessité de références directes entre les composants.
Gestion des dépendances 🔄
Gérer les dépendances est un aspect crucial de la réduction du couplage. Dans le développement moderne, les dépendances sont souvent gérées par des frameworks ou des conteneurs. Toutefois, ce concept s’applique même en l’absence d’outils spécifiques.
Injection par le constructeur
Passer les dépendances par le constructeur garantit que les composants requis sont disponibles au moment de l’instanciation de l’objet. Cela rend les dépendances explicites et obligatoires.
- Empêche la création d’objets dans un état invalide.
- Rend l’objet immuable en ce qui concerne ses dépendances.
- Facilite les tests plus simples en permettant de passer des objets fictifs.
Localisateurs de services
Bien qu’ils soient parfois utilisés pour éviter de passer des objets d’un endroit à un autre, les localisateurs de services peuvent introduire des dépendances cachées. Le code ne précise pas explicitement ce dont il a besoin ; il interroge le localisateur. Cela peut rendre le système plus difficile à comprendre et à suivre.
- Privilégiez l’injection explicite aux recherches implicites.
- Assurez-vous que l’emplacement des dépendances soit clair dans le code.
Implications des tests 🧪
Un faible couplage est la fondation d’un test efficace. Lorsque les composants sont découplés, ils peuvent être testés de manière isolée. Cela conduit à des suites de tests plus rapides et à une validation plus fiable.
Tests unitaires
Avec un couplage lâche, les tests unitaires se concentrent sur la logique d’une seule classe. Ils n’ont pas besoin d’instancier de bases de données ou de connexions réseau. Cela donne des tests qui s’exécutent en millisecondes.
- Isoler la classe sous test des services externes.
- Utilisez l’injection de dépendances pour fournir des doubles de test.
- Concentrez-vous sur le comportement plutôt que sur l’implémentation.
Tests d’intégration
Même avec un faible couplage, les tests d’intégration sont nécessaires pour vérifier que les composants fonctionnent ensemble. Toutefois, la portée est réduite car les détails internes de chaque composant sont considérés comme fiables.
- Concentrez-vous sur le contrat entre les composants.
- Vérifiez le flux de données à travers les frontières.
- Minimisez le nombre de points d’intégration qui nécessitent une vérification.
Péchés courants ⚠️
Atteindre un faible couplage n’est pas sans défis. Les développeurs tombent souvent dans des pièges qui réintroduisent des dépendances.
Sur-abstraction
Créer trop d’interfaces peut ajouter de la complexité sans réduire le couplage. Si chaque classe possède une interface, le code devient plus difficile à naviguer. Les interfaces doivent être créées là où elles apportent de la valeur, et non comme une règle.
État global
Utiliser des variables globales ou des méthodes statiques crée un couplage commun. Toute partie du système peut accéder ou modifier ces états, ce qui rend le flux de données imprévisible.
- Évitez l’état statique qui persiste entre les requêtes.
- Passez l’état explicitement par les paramètres de méthode.
- Utilisez l’injection de dépendances pour gérer l’état partagé.
Objets-Dieux
Un « objet-dieu » est une classe qui sait trop ou fait trop. Elle devient un centre de dépendances, créant un fort couplage avec tout ce qu’elle touche.
- Réfacter les objets-dieux en classes plus petites et spécialisées.
- Appliquez le principe de responsabilité unique.
- Limitez le nombre de méthodes et de champs de données dans une seule classe.
Évaluation de la flexibilité 📊
Comment savoir si votre système est suffisamment souple ? Plusieurs indicateurs suggèrent que le couplage a été réduit avec succès.
- Localisation des modifications :Les modifications dans un module n’impliquent pas de modifications dans les autres.
- Testabilité :Les modules peuvent être testés sans configuration complexe.
- Remplaçabilité :Les implémentations peuvent être échangées sans modifier le consommateur.
- Développement parallèle :Plusieurs développeurs peuvent travailler sur des modules différents sans conflit.
Refactoring pour l’indépendance 🛠️
Le refactoring est le processus d’amélioration de la structure interne du code sans modifier son comportement externe. Lors de la réduction du couplage, le refactoring est souvent nécessaire pour rompre les dépendances existantes.
Extraire une méthode
Déplacer la logique d’une méthode longue vers une nouvelle méthode. Cela peut aider à séparer les préoccupations et à réduire le couplage au sein d’une seule classe.
Remplacer la logique conditionnelle par de la polymorphie
Les instructions switch qui gèrent différents types peuvent être remplacées par un comportement polymorphe. Cela supprime la nécessité pour l’appelant de connaître le type spécifique, réduisant ainsi le couplage aux détails d’implémentation.
Introduire des interfaces
Si deux classes partagent un comportement mais ne sont pas liées, introduisez une interface qui définit ce comportement. Cela permet à d’autres classes de dépendre de l’interface plutôt que de la classe concrète.
Considérations finales 🏁
Réduire le couplage est un processus continu. Au fur et à mesure que les systèmes grandissent, de nouvelles dépendances apparaissent inévitablement. L’objectif n’est pas d’éliminer tout couplage, mais de le gérer efficacement. Un système sans couplage est impossible, mais un système avec un faible couplage bien géré est très résilient.
En privilégiant les interfaces, l’injection de dépendances et des frontières claires, les développeurs peuvent construire des architectures capables de résister aux changements. La flexibilité n’est pas une fonctionnalité ; c’est une qualité du design. Elle garantit que le système reste un outil de création de valeur métier plutôt qu’une source de dette technique.
Souvenez-vous que les décisions techniques ont des implications commerciales. Un système flexible réduit le délai de mise sur le marché des nouvelles fonctionnalités. Il diminue le risque d’erreurs de régression. Il permet à l’équipe de développement d’innover sans crainte de casser la fonctionnalité existante. Ce sont là les bénéfices concrets de se concentrer sur la réduction du couplage.
Commencez par auditer votre base de code actuelle. Identifiez les zones à fort couplage et priorisez-les pour la refonte. Des changements petits et progressifs sont souvent plus efficaces que des révisions importantes et risquées. Documentez les interfaces et les dépendances afin d’assurer la clarté. Enfin, encouragez une culture où le dé-couplage est valorisé comme une pratique standard, et non comme une exception.
En fin de compte, la force d’une conception orientée objet réside dans sa capacité à s’adapter. En réduisant le couplage, vous construisez une fondation qui soutient la croissance, le changement et l’évolution. Tel est l’essence de l’ingénierie logicielle durable.