











Dans l’écosystème complexe du développement logiciel, la clarté est la monnaie la plus précieuse. Alors que le code définit le comportement, la structure définit la stabilité. Les diagrammes de paquetages servent de plan de stabilité, offrant une vue d’ensemble de l’organisation du système. Ils masquent les détails d’implémentation pour se concentrer sur les relations, les dépendances et les frontières entre les modules. Comprendreles modèles de diagrammes de paquetages permet aux architectes de concevoir des systèmes maintenables, évolutifs et résilients aux changements.
Ce guide explore les structures architecturales standard présentes dans les diagrammes de paquetages. Il va au-delà de la syntaxe basique pour examiner la logique derrière le regroupement, les règles de dépendance et les implications des choix structurels. En reconnaissant ces modèles, les équipes peuvent aligner leurs modèles visuels avec leurs objectifs d’ingénierie.
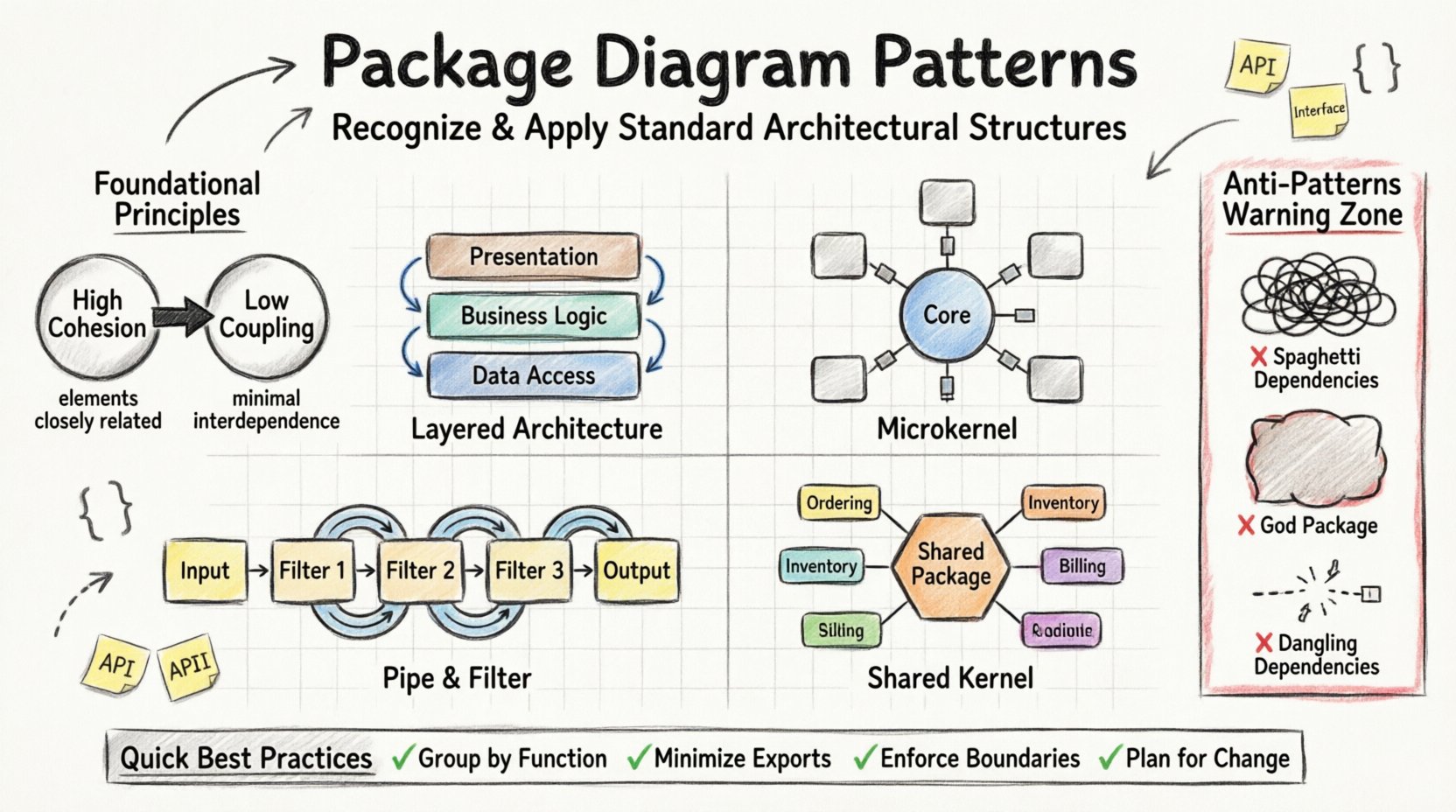
🧱 Principes fondamentaux de l’organisation des paquetages
Avant d’appliquer des modèles spécifiques, il faut comprendre les mécanismes fondamentaux qui régissent les diagrammes de paquetages. Ces diagrammes ne sont pas simplement des ornements visuels ; ils représentent des frontières logiques. Deux principes fondamentaux déterminent l’efficacité de toute structure de paquetage :
- Cohésion :Les éléments d’un paquetage doivent être étroitement liés. Si un paquetage contient des fonctionnalités non liées, il devient difficile à comprendre et à modifier. Une forte cohésion garantit qu’un changement dans une zone ne se propage pas de manière imprévisible à l’ensemble du système.
- Couplage :Cela mesure le degré d’interdépendance entre les paquetages. Un faible couplage est l’objectif. Lorsque les paquetages dépendent d’implémentations spécifiques plutôt que d’abstractions, le système devient rigide. Les modèles efficaces minimisent le couplage pour permettre une évolution indépendante.
Les diagrammes de paquetages visualisent ces concepts. Les flèches indiquent les dépendances. Le sens de la flèche montre quel paquetage dépend de l’autre. Un diagramme bien conçu montre un flux clair d’information, en évitant les tissus emmêlés de dépendances circulaires.
🔍 Reconnaître les modèles architecturaux standards
Les modèles architecturaux sont des solutions récurrentes aux problèmes courants. Dans le contexte des diagrammes de paquetages, ces modèles définissent comment les paquetages sont organisés et interagissent. Identifier le bon modèle dès le départ évite les dettes structurelles plus tard.
1. Architecture en couches
Le modèle en couches est probablement la structure la plus courante dans les systèmes d’entreprise. Il organise les paquetages en couches horizontales selon leur niveau d’abstraction ou leur responsabilité. Chaque couche n’interagit qu’avec la couche immédiatement inférieure.
- Structure :Les paquetages sont empilés verticalement. La couche supérieure (par exemple, Présentation) dépend de la couche du milieu (par exemple, Logique métier), qui elle-même dépend de la couche inférieure (par exemple, Accès aux données).
- Règle de dépendance :Les dépendances doivent s’écouler dans une seule direction. La couche supérieure ne peut pas dépendre directement de la couche inférieure. Cela impose une séparation des préoccupations.
- Avantage :Il simplifie le test et permet d’échanger des couches sans affecter les autres, à condition que les interfaces restent stables.
2. Architecture micro-noyau
Ce modèle sépare la fonctionnalité centrale des extensions. Il est idéal pour les systèmes qui nécessitent une extensibilité, comme les IDEs ou les plateformes de gestion de contenu.
- Structure :Un paquetage central contient la logique principale. Autour de lui se trouvent plusieurs paquetages d’extensions.
- Règle de dépendance :Le paquetage central définit des interfaces. Les paquetages d’extensions les implémentent. Le paquetage central ne dépend jamais des extensions, mais les extensions dépendent du noyau.
- Avantage :De nouvelles fonctionnalités peuvent être ajoutées sans modifier le système central, réduisant ainsi le risque de régression.
3. Canal et filtre
Idéal pour les pipelines de traitement de données, ce modèle divise le système en unités de traitement (filtres) connectées par des flux de données (canaux).
- Structure : Chaque package représente une étape de transformation spécifique. Les données circulent d’un package au suivant.
- Règle de dépendance : Les filtres dépendent du schéma de données mais pas les uns des autres. Ils communiquent via le canal (interface).
- Avantage : Haute réutilisabilité. Un filtre conçu pour un pipeline peut être réutilisé dans un autre si le format des données correspond.
4. Noyau partagé
Ce modèle implique plusieurs sous-systèmes partageant un ensemble commun de packages. Il est utile lorsque des produits distincts partagent une grande partie de logique centrale.
- Structure : Un package central contient le code partagé. Les packages périphériques contiennent le code unique pour des sous-systèmes spécifiques.
- Règle de dépendance : Les packages périphériques dépendent du noyau partagé. Le noyau partagé doit rester stable et inchangé.
- Avantage : Réduit la duplication. Assure la cohérence entre différents produits ou modules.
📊 Comparaison des modèles structurels
Le tableau suivant résume les caractéristiques clés de ces modèles pour faciliter le choix.
| Modèle | Objectif principal | Direction de dépendance | Meilleur cas d’utilisation |
|---|---|---|---|
| En couches | Séparation des préoccupations | Du haut vers le bas | Applications d’entreprise |
| Micro-noyau | Extensibilité | Du noyau vers l’extension | Systèmes basés sur des plugins |
| Pipe et filtre | Transformation des données | Flux séquentiel | ETL, traitement des données |
| Noyau partagé | Réutilisation du code | Radial (vers l’extérieur) | Familles de produits |
⚠️ Identification des anti-modèles
Tout comme il existe des structures standard, il existe des pièges courants qui dégradent la qualité du système. Reconnaître ces anti-modèles est aussi important que d’identifier les modèles valides.
1. Dépendances spaghetti
Cela se produit lorsque les paquets ont de nombreuses dépendances non structurées. Il n’y a pas de flux ou de hiérarchie claire. Le diagramme ressemble à un entrelacs désordonné.
- Signes : De nombreux flèches croisant entre les paquets. Des dépendances circulaires où le paquet A dépend de B, et B dépend de A.
- Impact : Les modifications deviennent dangereuses. Corriger un bogue dans un paquet peut endommager la fonctionnalité dans plusieurs autres.
2. Le paquet Dieu
Un paquet qui contient trop de responsabilités. Il agit comme un dépotoir pour les classes qui ne trouvent pas leur place ailleurs.
- Signes : Un seul paquet avec un nombre disproportionné de classes par rapport aux autres.
- Impact : Faible cohésion. Le paquet devient un goulot d’étranglement pour le développement et une source de couplage élevé.
3. Dépendances pendantes
Des dépendances existent qui ne sont pas réellement utilisées, ou des dépendances vers des paquets qui n’existent pas dans la version finale de construction.
- Signes : Des instructions d’importation qui font référence à des chemins de code qui sont morts ou supprimés.
- Impact : Des échecs de construction et de la confusion lors de la refonte.
🛠️ Application des modèles aux systèmes existants
Refactoriser un système existant pour qu’il s’aligne sur des modèles architecturaux standards exige une approche méthodique. Il ne suffit pas de dessiner un nouveau diagramme ; le code doit refléter le modèle.
- Évaluer l’état actuel :Générer un diagramme de paquetages à partir de la base de code existante. Identifier le modèle dominant (le cas échéant) et les anti-modèles présents.
- Définir les limites :Déterminer où se situent les limites logiques. Ne pas diviser les paquetages uniquement sur la base des noms de fichiers ; diviser en fonction de la fonctionnalité et de la propriété des données.
- Introduire des interfaces :Pour réduire le couplage, introduire des interfaces entre les paquetages. Cela permet au comportement d’être modifié sans affecter le consommateur.
- Refactoring itératif :Déplacer les classes par petits groupes. S’assurer que les tests passent après chaque déplacement. Ne pas tenter de restructurer l’ensemble du système en une seule version.
- Mettre à jour la documentation :Le diagramme de paquetages doit être mis à jour immédiatement après toute modification structurelle. Si le modèle n’est pas à jour, il devient trompeur.
🔒 Gestion des dépendances et des interfaces
La santé d’une structure de paquetages dépend de la manière dont les dépendances sont gérées. Cela implique des règles strictes sur ce qu’un paquetage peut accéder.
Inversion de dépendance
Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau. Les deux doivent dépendre d’abstractions. En termes de paquetages, cela signifie qu’un paquetage de logique métier ne doit pas dépendre directement d’un paquetage de base de données. Il doit plutôt dépendre d’une interface définie dans un paquetage commun.
- Règle :Les abstractions ne doivent pas dépendre des détails. Les détails doivent dépendre des abstractions.
- Avantage :Cela découple la logique métier du mécanisme de persistance, permettant des tests plus faciles et le remplacement des bases de données.
Stabilité des paquetages
Tous les paquetages ne sont pas égaux. Certains sont stables et largement utilisés ; d’autres sont volatils et spécifiques à un module. Le Règle de dépendancestipule que la stabilité dépend de la direction.
- Direction :Les paquetages stables ne doivent pas dépendre des paquetages instables.
- Raison :Si un paquetage stable dépend d’un paquetage instable, les modifications dans le paquetage instable contraindront des modifications dans le paquetage stable, annulant ainsi sa stabilité.
- Application :Les paquetages d’infrastructure centrale doivent rester en bas du graphe de dépendance. Les paquetages spécifiques à l’application doivent être placés en haut.
🔄 Maintenance et évolution
Une structure de paquetages n’est pas une configuration ponctuelle. Elle évolue avec la croissance du système. Une maintenance continue est nécessaire pour éviter la dégradation structurelle.
- Revue de code :Inclure la structure des paquets dans les revues de code. Demandez : « Ce nouveau classe appartient-il à un paquet existant, ou en nécessite-t-il un nouveau ? »
- Indicateurs :Suivre des indicateurs tels que le couplage et la cohésion. Les outils automatisés peuvent mettre en évidence les paquets qui dépassent les seuils de dépendance.
- Sprints de refactoring :Allouer du temps dans le cycle de développement pour traiter la dette technique liée à l’architecture. Ne la laissez pas s’accumuler.
- Standardisation :Établir des conventions de nommage pour les paquets. Utiliser une hiérarchie cohérente (par exemple,
com.organization.project.module) pour rendre la structure prévisible.
📈 L’impact de la structure sur les performances
Bien que les diagrammes de paquets soient des vues logiques, ils ont des implications physiques. La manière dont les paquets sont compilés et déployés affecte les performances.
- Temps de chargement :Si un paquet contient une logique d’initialisation lourde, cela peut ralentir le démarrage du système. Séparez les paquets d’initialisation de la logique d’exécution.
- Empreinte mémoire :Un couplage étroit peut entraîner le chargement de modules entiers pour accéder à une seule classe. La modularisation permet un chargement différé des fonctionnalités.
- Développement parallèle :Des limites de paquet bien définies permettent à plusieurs équipes de travailler sur des modules différents sans conflits de modifications. Cela augmente la vitesse globale.
🧭 Questions directrices pour la conception
Lors de la création ou de la revue d’un diagramme de paquet, posez ces questions pour valider la conception :
- Y a-t-il une seule raison pour qu’un paquet change ? (Principe de responsabilité unique)
- Les classes de ce paquet partagent-elles le même niveau d’abstraction ?
- Y a-t-il des dépendances circulaires entre les paquets ?
- Peut-on comprendre ce paquet sans consulter son implémentation interne ?
- La direction des dépendances correspond-elle au flux de la logique métier ?
🎯 Résumé des meilleures pratiques
Une conception efficace des paquets repose sur la discipline et le respect de modèles éprouvés. Elle exige un changement de perspective, passant de la pensée en termes de fichiers à celle en termes de modules logiques.
- Regrouper par fonction :Ne pas regrouper par type (par exemple, tous les « Utils » dans un même endroit). Regrouper par fonction ou domaine.
- Minimiser les exports : Expose uniquement ce qui est nécessaire. Gardez les détails d’implémentation cachés au sein des paquets.
- Imposer les limites : Utilisez des outils et des vérifications pour empêcher les paquets de s’importer mutuellement de manière interdite.
- Consistance visuelle : Assurez-vous que le diagramme reflète la réalité du code. Les écarts entraînent de la confusion.
- Prévoir les changements : Supposons que le système évoluera. Concevez des limites capables d’accueillir de nouvelles fonctionnalités sans briser les existantes.
Le choix du modèle dépend du contexte spécifique du projet. Un micro-noyau pourrait être excessif pour une utilitaire simple, tandis qu’une approche en couches pourrait être insuffisante pour un flux de données en temps réel. Le rôle de l’architecte consiste à choisir la structure qui équilibre le mieux stabilité, flexibilité et complexité.
En maîtrisant la reconnaissance et l’application de ces structures, les équipes construisent des systèmes plus faciles à comprendre et moins coûteux à maintenir. Le diagramme de paquet est la carte qui guide l’équipe à travers la complexité de la base de code. Assurez-vous que la carte est précise, et le parcours sera plus fluide.
Souvenez-vous, l’architecture ne consiste pas à dessiner de jolis dessins. Elle consiste à gérer la complexité. Chaque ligne tracée et chaque dépendance établie doit avoir une raison d’être. Lorsque la structure sert les objectifs métiers, le logiciel génère de la valeur.
🔗 Étapes suivantes pour la mise en œuvre
Pour commencer à appliquer ces concepts :
- Revoyez le diagramme de paquet de votre système actuel.
- Identifiez le modèle dominant actuellement utilisé.
- Listez les trois principaux anti-modèles causant des frictions.
- Sélectionnez un modèle à refactoriser lors du prochain sprint.
- Mettez à jour la documentation pour refléter la nouvelle structure.
L’amélioration continue du modèle architectural garantit que le système reste en phase avec les capacités de l’équipe et les exigences du marché.