











Introduction
Dans le paysage en constante évolution de l’architecture logicielle moderne, le pont entre un modèle de domaine orienté objet et une base de données relationnelle reste l’une des couches les plus complexes à maintenir. Depuis des décennies, les développeurs luttent contre le décalage d’impédance entre les objets Java et les tables SQL, passant souvent beaucoup de temps à écrire, déboguer et optimiser des requêtes SQL brutes. À mesure que la logique métier devient plus complexe, la difficulté de gérer manuellement ces interactions avec la base de données augmente également.
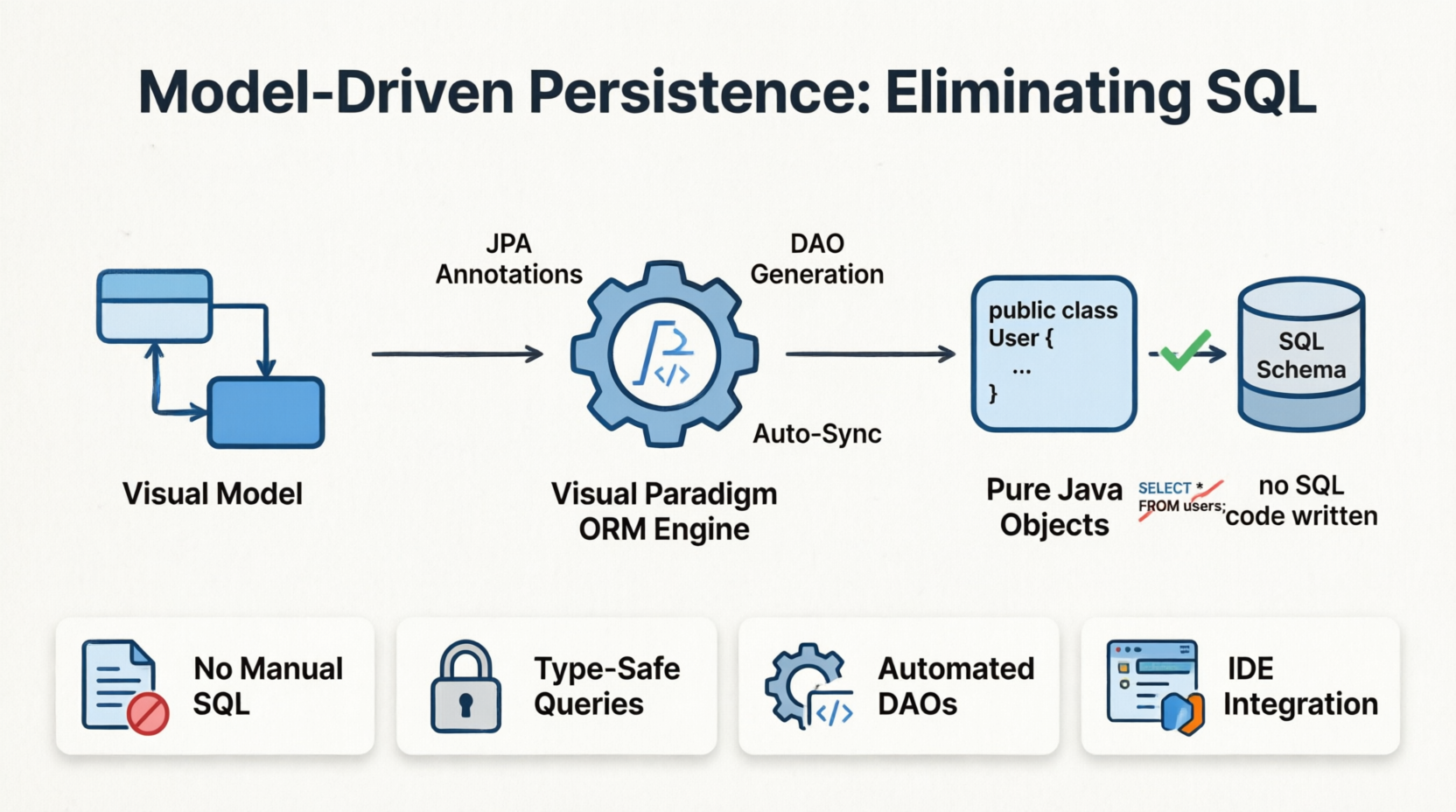
Cette étude de cas explore une approche transformatrice de la persistance des données :Programmation de base de données sans SQL. En exploitant les outils de mappage objet-relationnel (ORM) dans Visual Paradigm, les équipes de développement peuvent déplacer leur attention de la syntaxe de base de données de bas niveau vers la modélisation de domaine de haut niveau. Ce guide montre comment concevoir, générer et gérer une couche de persistance robuste à l’aide de Hibernate et de NHibernate, permettant aux développeurs de manipuler les enregistrements de base de données entièrement à travers des objets Java purs ou des objets .NET. Le résultat est un code plus propre, un temps de développement réduit, et une intégration fluide entre la modélisation visuelle et le code exécutable.
Persistance des objets Java avec Hibernate
Le SQL peut être difficile à écrire et à déboguer, et deviendra encore plus difficile à mesure que votre schéma et votre logique métier deviennent plus complexes. Avez-vous déjà pensé à manipuler une base de données sans écrire une seule ligne de SQL ? Notre outil de mappage objet-relationnel (ORM) vous permet d’y parvenir.
Concevez simplement votre base de données avec notreoutil de diagramme entité-association (ERD) (ou pourréingénierer un ERD à partir de la base de données existante). Ensuite, générez la couche de mappage ORM Hibernate à partir de l’ERD, et c’est tout ! La bibliothèque d’objets générée vous permet d’accéder et de manipuler les enregistrements de base de données entièrement avecdes objets Java purs. Au revoir SQL !

Persistance des objets .NET avec NHibernate
Oubliez le temps et les efforts nécessaires pour écrire et déboguer du SQL. À partir de maintenant, vous pouvez accéder à la base de données via des objets persistants générés à partir d’ERD et du cadre NHibernate. Profitez d’un codage élégant – plus de SQL, plus de souffrance !

Intégration avec l’IDE
Effectuez la modélisation visuelle et le développement dans un environnement unifié –votre IDE préféré. Concevez le système et la base de données avec des diagrammes de classes et des ERD, générez les classes persistantes et programmez dans l’IDE. Pas de changement entre les fenêtres, pas de SQL, pas de tracas !

IDE populaires pris en charge (Eclipse/NetBeans/IntelliJ IDEA/Visual Studio/Android Studio)
Élevez votre expérience de développement logiciel à un nouveau niveau grâce à sonintégration transparente avec Eclipse, Visual Studio, NetBeans, IntelliJ IDEA et Android Studio.
Synchronisez entre l’ERD et le diagramme de classe UML
Générez un diagramme de classe à partir de l’ERD et synchronisez les modifications entre les deux, et inversement.
Reliez le modèle de classe et le modèle de données à l’aide du diagramme ORM
Le diagramme de mappage objet-relationnel (ORM) présente visuellement le mappage entre les classes et les entités.
Génération de code Hibernate à partir d’une base de données existante
Générer le code Hibernate ORM à partir d’une base de données existante.
Prise en charge des fichiers XML Hibernate et de JPA
Permettre de spécifier la manière dont les informations de mapping doivent être stockées.
Gestion des erreurs
Permettre de spécifier la manière dont les erreurs sont gérées lorsqu’elles se produisent.
Gestion des exceptions
Permettre de spécifier la manière dont les exceptions sont gérées lorsqu’elles se produisent.
Initialisation différée des collections
Réduire le chargement de la base de données. Éviter le chargement des objets lorsque l’objet principal est chargé avec l’option « lazy ».
Gestion différente des associations
Permettre de spécifier le comportement de mise à jour lors de la mise à jour d’une association bidirectionnelle.
Prise en charge des méthodes statiques, des usines, des DAO et des POJO
Permettre de spécifier la manière dont les objets peuvent être récupérés avec le code généré.
Options de cache
Améliorer les performances en configurant le cache de deuxième niveau.
Sélection facultative des fichiers JAR
Inclure les bibliothèques facultatives et les pilotes JDBC dans le fichier orm.jar généré.
Générer du code et un exemple de servlet
Générer des fichiers d’exemple qui vous apprennent à travailler avec le code généré.
Générer une page JSP
Générer un exemple de page Java Server Page (JSP).
Générer le filtre et le descripteur d’application Web
Générer le fichier web.xml essentiel au développement d’applications Web
Reverse-engineering du modèle ORM à partir des fichiers de mapping Hibernate
Former automatiquement le modèle de persistance ORM à partir des fichiers de mapping Hibernate générés.
Maîtriser la génération ORM : un guide pour Visual Paradigm et Hibernate
Dans l’architecture logicielle moderne, le pont entre un modèle de domaine orienté objet et une base de données relationnelle est souvent la couche la plus complexe à maintenir.Visual Paradigm (VP)fournit un moteur de génération ORM (mapping objet-relationnel) robuste qui automatise la création des classes Java/Persistence, des fichiers de mapping et des schémas de base de données directement à partir de vos modèles UML.
1. Préparation : La fondation du modèle
Avant de déclencher l’assistant, assurez-vous que votre projet est « prêt à la persistance » :
-
Consistance du modèle : Assurez-vous que votre Diagramme de classes UML ou MCD est finalisé.
-
Le marqueur « Persistable » : Seules les classes marquées comme « Persistable » (via la spécification de classe ou le stéréotype) seront traitées.
-
Synchronisation : Si vous avez commencé par un MCD, utilisez l’outil de synchronisation de VP pour le mapper d’abord vers un diagramme de classes.
2. Configuration de l’assistant de génération
Accédez à Outils > Hibernate > Générer du code… pour ouvrir la boîte de dialogue de génération du code de base de données.
Paramètres d’exécution principaux
| Paramètre | Objectif | Choix recommandé |
|---|---|---|
| Générer | Définit la sortie (code, base de données ou les deux). | Code et base de données |
| Langage | Le langage de programmation cible. | Java (par défaut) |
| Code vers | Le contexte d’environnement. | Autonome (pour la plupart) |
| Framework | Style de mappage. | Annotations JPA (Modern) |
3. Conception de la couche de persistance
La puissance de VP réside dans sa capacité à définir l’architecture de votre couche d’accès aux données à l’aide de quelques interrupteurs.
Architecture et modèles d’API
Sélectionnez un API persistante qui correspond à la complexité de votre projet :
-
DAO (avec interface) : La « norme or ». Il génère des interfaces et des implémentations, ce qui rend votre code testable unitairement et facile à remplacer.
-
Méthodes statiques : Idéal pour la protoypation rapide ; les opérations CRUD sont appelées directement sur l’entité (par exemple,
User.save()). -
API Critères : Activez toujours Générer les critères. Cela vous permet d’écrire des requêtes typées en Java plutôt que des chaînes brutes HQL ou SQL.
Gestion des erreurs et des exceptions
Ne laissez pas votre application échouer en silence.
-
Gestion des erreurs : Définissez ceci sur Lancer RuntimeException afin d’éviter le bazar des « exceptions vérifiées » tout en garantissant que les échecs de base de données soient toujours capturés.
-
Journalisation : Utilisez Imprimer dans log4j pour les environnements de production afin de garantir que les traces de base de données soient capturées dans vos journaux standards.
4. Optimisation des performances : Récupération et Associations
La manière dont votre application gère les relations entre les données détermine sa vitesse.
-
Initialisation différée des collections : Défini sur Supplémentaire. Cela fournit un compromis où les collections sont chargées de manière différée, mais le framework gère automatiquement la synchronisation des associations bidirectionnelles.
-
Gestion intelligente des associations : Ceci est une fonctionnalité « indispensable ». Elle garantit que si vous ajoutez un Élément à une Catégorie, la Catégorie est automatiquement mise à jour du côté de l’Élément, préservant ainsi l’intégrité référentielle en mémoire.
5. Affinements avancés
Cliquez sur Paramètres avancés bouton pour un contrôle granulaire sur le « style » du code généré :
-
Types de collections : Choisissez
Setpour des contraintes uniques ouListepour des données ordonnées. -
Mappage des dates : Mappage des données temporelles précisément comme
Date,Heure, ouHorodatage. -
Génération de ToString() : Utilisez Clé métier ou ID uniquement pour éviter les boucles de références circulaires dans vos journaux.
6. Du modèle à la base de données (DDL)
Sous le Onglet Base de données, vous pouvez combler le fossé avec le monde physique :
-
Export vers la base de données : VP générera le DDL et l’exécutera sur votre base de données cible.
-
Mode DB : Utiliser Mise à jour pour évoluer un schéma existant ou Supprimer et créer pour un environnement de développement frais.
-
Données d’exemple : Cochez cette case pour que VP insère automatiquement des lignes de test en fonction des attributs de votre modèle.
Liste de contrôle récapitulative pour les normes 2026
Framework : JPA (Annotations)
API : DAO avec interface
Récupération : Lente (supplémentaire)
Requête : Activer l’API Critères
Validation : Activer les annotations de validateur (Paramètres avancés)
Conclusion
La transition du script SQL manuel à la génération d’ORM pilotée par modèle représente une avancée significative en matière d’efficacité en génie logiciel. En utilisant les outils intégrés de Visual Paradigm, les développeurs peuvent éliminer le processus fastidieux et sujet aux erreurs de rédaction de SQL brut, en le remplaçant par une modélisation visuelle intuitive et une génération automatisée de code.
Que vous travailliez avec Java/Hibernate ou .NET/NHibernate, la capacité à synchroniser les diagrammes ERD avec les diagrammes de classes UML et à générer des DAO robustes garantit que le niveau de persistance reste cohérent, maintenable et performant. Comme illustré dans cette étude de cas, adopter des bonnes pratiques telles que l’utilisation d’annotations JPA, l’implémentation d’interfaces DAO et l’utilisation du chargement différé ne simplifie pas seulement le développement, mais protège également les applications contre la complexité croissante des architectures de données modernes. Pour les équipes cherchant à accélérer la livraison sans sacrifier la qualité, la programmation de bases de données sans SQL n’est plus simplement une possibilité — c’est une nécessité stratégique.
Références
- Aperçu des outils Hibernate ORM de Visual Paradigm: Cette ressource fournit un aperçu des outils intégrés conçus pourla génération de code Hibernate ORM, y compris les classes d’entité, les DAO et les schémas de base de données générés directement à partir de modèles UML.
- Comment générer du code Hibernate ORM et un schéma de base de données dans Visual Paradigm: Un guide technique offrant des instructions étape par étape pourla production de code compatible Hibernateet de schémas à partir de modèles visuels.
- Définition d’implémentations personnalisées pour l’ORM dans Visual Paradigm: Ce tutoriel montre commentpersonnaliser la génération de code ORMen définissant des modèles et des implémentations spécifiques pour les classes Java d’entité et de DAO.
- Simplification de l’implémentation Hibernate avec Visual Paradigm: Un guide complet sur l’utilisation deun développement piloté par modèlepour simplifier l’implémentation Hibernate et maintenir la synchronisation avec les bases de données.
- Comment générer du code ORM à partir d’un diagramme de classes dans Visual Paradigm: Cette ressource explique le processus d’utilisation dedes diagrammes de classes UMLpour générer du code ORM compatible Hibernate ou JPA afin de développer des logiciels de manière efficace.
- Tutoriel Hibernate Criteria pour les développeurs Java: Un tutoriel pratique axé sur l’utilisation del’API Hibernate Criteriapour créer des requêtes de base de données sécurisées par le type et dynamiques au sein des applications Java.
- Génération de modèles ORM dans Visual Paradigm: Une documentation détaillée expliquant commentgénérer des modèles ORM à partir de bases de données existantes faciliter l’ingénierie pilotée par les modèles.
- Génération d’ORM à partir d’une base de données dans Visual Paradigm: Instructions sur le reverse-engineering d’une base de données pour produire des modèles ORM à l’aide d’outils d’automatisation intégrés.
- Débloquez le pouvoir de la modélisation des données avec l’outil ERD pour ORM et Hibernate: Cet article met en évidence comment le outil ERD prend en charge les frameworks ORM et Hibernate pour une cartographie fluide et une génération de code.
- Guide d’intégration et d’utilisation de Hibernate: Une ressource spécialisée sur les bases de connaissances couvrant l’intégration de Hibernate, la configuration et les fonctionnalités avancées au sein de l’environnement de modélisation.