











设计复杂的软件系统不仅仅需要编写代码。它要求清晰地理解不同组件之间的交互方式、边界所在位置,以及如何随着时间保持灵活性。可视化这种结构最有效的工具之一就是UML包图。在本指南中,我们将通过一个详细的案例研究来建模图书馆系统。我们将探讨如何识别逻辑分组、管理依赖关系,并在不依赖特定工具或技术的情况下创建可扩展的架构。 🏗️
🧠 理解软件架构中的包图
包图表示系统元素被组织成组或包的方式。它是一种结构图,关注代码的高层组织,而非单个类的细节。可以将包想象成一个包含相关功能的文件夹,以确保代码保持有序且易于维护。
为什么这很重要?当系统规模扩大时,类、接口和模块的数量会呈指数级增长。如果没有清晰的结构,代码库就会变成一团乱麻,被称为“意大利面式代码”。包图帮助架构师和开发者在观察细节之前先看到整体。它回答了关键问题:
- 系统的哪些部分依赖于其他部分?
- 稳定的边界在哪里?
- 我们如何将变更限制在特定区域?
- 模块之间存在哪些接口?
在处理交易、用户数据和目录管理的图书馆系统背景下,这些问题至关重要。结构不良的包层次可能导致紧密耦合,即图书目录的任何更改都会迫使用户登录模块也进行修改。正确的建模可以防止这种脆弱性。
📖 定义范围:图书馆生态系统
为了创建一个准确的模型,我们必须首先定义系统的功能范围。现代图书馆系统不仅仅是卡片目录;它是一个数字生态系统。它需要处理会员注册、图书库存、借阅交易、罚款以及报告。让我们分解出构成我们包的基础的主要功能领域。
考虑以下核心功能:
- 会员管理:注册、资料更新和身份验证。
- 库存管理:添加、更新和搜索图书与媒体。
- 交易处理:借出物品、归还物品和预订物品。
- 财务:计算罚款和管理付款。
- 报告:生成流通量和受欢迎程度的统计数据。
这些领域中的每一个都代表一个潜在的包。然而,仅根据功能进行分组有时会导致碎片化。我们还必须考虑技术层次。一个健壮的架构通常将关注点分离为数据访问、业务逻辑和表示层等层次。在本案例研究中,我们将采用一种混合方法,结合功能性和逻辑性关注点,以创建紧密集成的包。
🔍 识别逻辑包
建模的第一步是识别包。我们希望将经常一起更改的元素分组(内聚性),同时尽量减少不相关组之间的依赖关系(耦合)。让我们为我们的图书馆系统提出一组包。
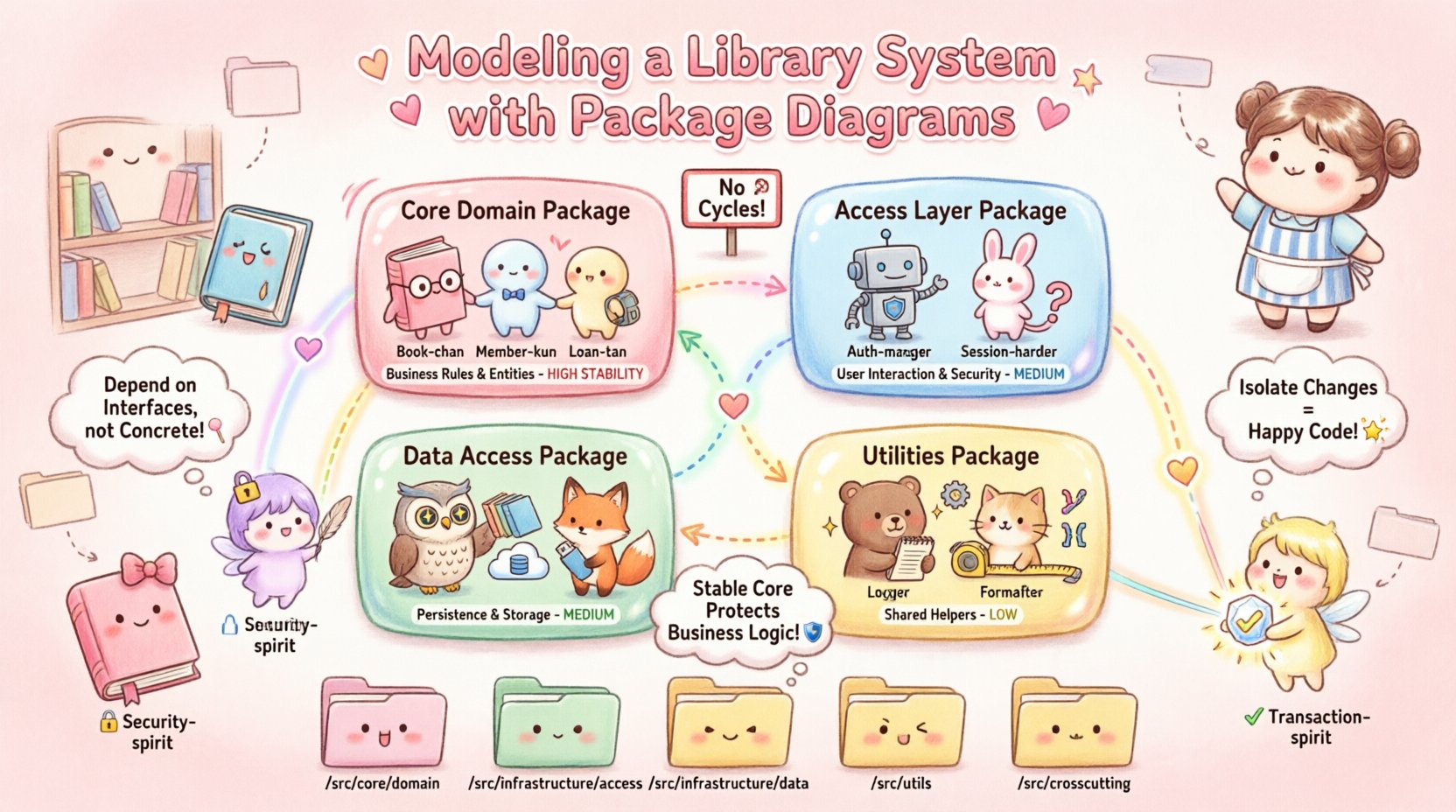
1. 核心领域包
该包包含基本的业务实体。它代表了系统的“真实”状态。在图书馆背景下,这包括图书, 成员, 贷款,以及项目 类。这个包应该是系统中最稳定的部分。其他包应该依赖它,但它本身不应依赖其他包来运行。
2. 访问层包
这个包处理与外部世界的接口。它管理用户会话、认证令牌和输入验证。它充当网关。它不包含业务规则;它只是将数据传递给核心领域。
3. 数据访问包
这个包负责持久化。它知道如何将一个图书保存到数据库,或检索贷款列表。它直接与存储机制交互。通过将这部分隔离,我们可以在不影响业务逻辑的情况下更换底层存储技术。
4. 工具与支持包
这个包包含不属于特定领域的共享服务。例如包括日期格式化、货币计算辅助工具和日志记录机制。将它们单独分离可以防止它们污染业务逻辑包。
| 包名称 | 职责 | 关键类 | 稳定性 |
|---|---|---|---|
| 核心领域 | 业务规则和实体 | 图书、成员、贷款 | 高 |
| 访问层 | 用户交互和安全 | 认证管理器、会话处理器 | 中等 |
| 数据访问 | 持久化和存储 | 仓库、数据库连接器 | 中等 |
| 实用工具 | 共享的辅助函数 | 格式化器、日志器 | 低 |
如表所示,核心域是最稳定的。这是一个关键的架构原则。如果核心域频繁变化,整个系统将变得不稳定。通过将其隔离,我们可以保护核心业务逻辑,使其免受用户界面变化等易变外部因素的影响。
🔗 管理依赖关系和接口
一旦定义了包,接下来的挑战就是确定它们如何通信。在包图中,依赖关系由箭头表示。箭头的方向表示依赖的方向。如果包A依赖于包B,这意味着包A使用了包B的功能。
依赖规则
为了保持清晰的架构,我们应该遵循特定的依赖规则:
- 依赖规则:源代码依赖只能指向稳定代码。核心域不应依赖访问层。
- 无循环:包之间的循环依赖会导致两个包相互等待,使系统难以编译或运行。
- 接口隔离:包应依赖于接口,而不是具体的实现。这样即使实现发生变化,也不会破坏使用者。
可视化数据流
想象一下在借款场景中数据的流动。访问层接收来自用户的请求。它验证输入。然后调用核心域中的方法来处理贷款。核心域计算到期日。接着调用数据访问包来保存交易。数据流是单向的:访问层 → 核心域 → 数据访问。
这种结构确保了业务规则(核心域)保持纯净。它们不知道HTTP请求或数据库驱动程序。这种分离对于测试至关重要。你可以在不启动数据库或模拟网络请求的情况下测试核心域的逻辑。
🖼️ 可视化结构
在创建这些包的可视化表示时,清晰性是关键。图表不应杂乱无章,应能一眼看出它们之间的关系。以下是我们在可视化元素上的结构方式。
- 包框:为每个包使用不同的框,并清晰地标记标签。
- 依赖关系:使用带空心箭头的虚线来表示依赖关系。
- 接口:使用棒棒糖符号或特定图标来表示导出的接口。
- 分组:如果有子包,应通过视觉嵌套来显示层级关系。
考虑以下两者之间的关系:报告 包和 核心领域 报告包需要数据来生成统计信息。它应该依赖于核心领域。然而,它不应修改数据。这是一种只读依赖。在图中,这是一个标准的依赖箭头,但其语义含义与事务性依赖不同。
另一个关键的可视化方面是边界。包与系统其余部分之间的边界至关重要。数据访问 包与系统其余部分之间的边界非常重要。这是系统与物理世界交互的点。在图中,这个边界应该明显区分,或许用特定颜色或边框样式标记,以提醒开发人员此处的更改会影响性能和持久性。
💻 实现策略
这个图如何转化为实际的代码组织?包图是文件系统结构的蓝图。尽管不同编程语言对包和命名空间的处理方式不同,但逻辑分组保持一致。
对于一个图书馆系统,目录结构可能如下所示:
/src/core/domain– 包含Book.java,Member.java/src/core/service– 包含LoanService.java/src/infrastructure/access– 包含ApiGateway.java/src/infrastructure/data– 包含BookRepository.java/src/infrastructure/util– 包含DateUtils.java
注意这种映射。目录结构中的 core 包与 核心领域 图中的包。该 基础设施 文件夹包含技术细节。图表与文件系统之间的对齐至关重要。这确保了开发人员不会意外创建违反架构规则的依赖关系。如果开发人员试图从 基础设施 导入到 核心,构建系统或代码分析工具应将其标记出来。
⚙️ 处理横切关注点
并非所有关注点都能很好地归入单一包中。有些关注点贯穿整个系统,这些被称为横切关注点。例如包括日志记录、安全性和事务管理。
在包图中,这些通常被表示为独立的包,或作为现有包的构造型包含。例如,安全 关注点可能适用于 访问层 和 核心领域 同样适用。如果我们创建一个 安全 包,它提供接口,其他包可以使用这些接口来验证权限。
然而,必须小心。如果 安全 包变得过大,它就会成为所有内容的依赖项。这被称为“上帝包”。为了避免这种情况,应拆分安全关注点。将认证逻辑与授权逻辑分开。认证关乎身份(你是谁?)。授权关乎权限(你能做什么?)。在图书馆系统中,检查用户名和密码属于认证。检查成员是否可以借阅特定书籍属于授权。
| 关注点类型 | 示例 | 包位置 |
|---|---|---|
| 认证 | 登录验证 | 访问层 |
| 授权 | 权限检查 | 核心领域 |
| 日志记录 | 审计追踪 | 工具 |
| 事务 | 数据一致性 | 数据访问 |
通过分散这些关注点,我们避免了单点故障。如果日志记录机制发生变化,也不应影响认证流程。工具 包应提供一个标准的日志记录接口,供其他包实现。
🔄 重构与演进
软件永远不会完成;它会不断演进。包图是一个动态文档。随着图书馆系统的扩展,新的需求将不断出现。也许图书馆希望与外部数字档案系统集成。这需要创建新包或修改现有包。
在重构时,包图充当了地图。如果你需要将一个类从一个包移动到另一个包,必须先更新图表。这可以防止意外的依赖关系。例如,如果你将成员 类从核心领域 移动到访问层,你可能会破坏依赖于它的业务逻辑。图表能帮助你追踪这些影响。
重构还涉及删除包。如果某个功能被弃用,相应的包应被移除。但必须先处理依赖关系。如果报告 包不再需要,删除前请确保没有其他包依赖它。
⚠️ 常见的建模错误
即使经验丰富的架构师在创建包图时也会犯错。识别这些陷阱有助于设计出更健壮的系统。
- 过度抽象: 为小型系统创建过多的包。如果你只有10个类,不要创建10个包。应按逻辑进行分组。
- 抽象不足: 将所有内容都放入一个巨大的包中。这会导致之前提到的面条式代码问题。
- 忽视分层: 在同一个包中混合数据访问代码和业务逻辑。这会使测试变得困难。
- 静态耦合: 依赖静态导入或单例,使依赖关系变得隐式而非显式。
- 缺少接口: 直接依赖具体类。这会使系统变得僵化。始终依赖抽象。
对于图书馆系统,一个常见错误是将借阅逻辑直接放在会员包中。虽然它们相关,借阅却是会员与物品之间的交易。它应属于事务或核心领域包,而不仅仅局限于会员的上下文中。
📈 价值总结
使用包图对图书馆系统进行建模,为开发提供了清晰的路线图。它确立了边界,定义了关系,并确保系统能够在不因自身复杂性而崩溃的情况下持续扩展。通过将关注点分离到核心、访问和数据等逻辑包中,我们构建了一个更易于理解、测试和维护的系统。
这一过程需要纪律。开发者必须抵制将功能添加到错误包中的冲动。他们必须遵守设计阶段确立的依赖规则。当这些规则被遵循时,结果是一个能够抵御变化的系统。新功能可以添加,而无需重写核心逻辑。架构支持业务需求,而非阻碍它们。
最终,目标不仅仅是绘制一张图。目标是向所有相关人员传达系统的结构。从项目经理到初级开发人员,包图都充当了一种通用语言。它减少了歧义,并使团队对系统的工作方式达成一致。在图书馆系统这类复杂环境中,数据完整性和用户体验至关重要,这种一致性并非可选,而是成功所必需的。